
More Lessons from the LINQ Database Query Performance Land
July 19, 2011 2:00 PM by Daniel Chambers (last modified on July 19, 2011 2:20 PM)
Writing LINQ against databases using providers like LINQ to SQL and Entity Framework is harder than it first appears. There are many different ways to write the same query in LINQ and many of them cause LINQ providers to generate really horrible SQL. LINQ to SQL is quite the offender in this area but, as we’ll see, Entity Framework can write bad SQL too. The trick is knowing how to write LINQ that doesn’t result in horribly slow queries, so in this blog post we’ll look at an interesting table joining scenario where different LINQ queries produce SQL of vastly different quality.
Here’s the database schema:
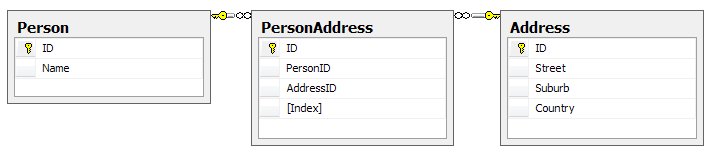
Yes, this may not be the best database design as you could arguably merge PersonAddress and Address, but it’ll do for an example; it’s the query structure we’re more interested in rather than the contents of the tables. One thing to note is that the Index column on PersonAddress is there to number the addresses associated with the person, ie Address 1, Address 2. There cannot be two PersonAddresses for the same person with the same Index. Our entity classes map exactly to these tables.
Let’s say we want to write a query for reporting purposes that flattens this structure out like so:

Optimally, we’d like the LINQ query to write this SQL for us (or at least SQL that performs as well as this; this has a cost of 0.0172):
SELECT p.Name, a1.Street AS 'Street 1', a1.Suburb AS 'Suburb 1', a1.Country AS 'Country 1',
a2.Street AS 'Street 2', a2.Suburb AS 'Suburb 2', a2.Country AS 'Country 2'
FROM Person p
LEFT OUTER JOIN PersonAddress pa1 on p.ID = pa1.PersonID AND pa1.[Index] = 1
LEFT OUTER JOIN PersonAddress pa2 on p.ID = pa2.PersonID AND pa2.[Index] = 2
LEFT OUTER JOIN [Address] a1 on a1.ID = pa1.AddressID
LEFT OUTER JOIN [Address] a2 on a2.ID = pa2.AddressID
One way of doing this using LINQ, and taking advantage of navigation properties on the entity classes, might be this:
from person in context.People
let firstAddress = person.PersonAddresses.FirstOrDefault(pa => pa.Index == 1).Address
let secondAddress = person.PersonAddresses.FirstOrDefault(pa => pa.Index == 2).Address
select new
{
Name = person.Name,
Street1 = firstAddress.Street,
Suburb1 = firstAddress.Suburb,
Country1 = firstAddress.Country,
Street2 = secondAddress.Street,
Suburb2 = secondAddress.Suburb,
Country2 = secondAddress.Country,
}
However, using LINQ to SQL, the following SQL is generated (and its cost is 0.0458, which is nearly three times the cost of the SQL we’re aiming for):
SELECT [t0].[Name], (
SELECT [t3].[Street]
FROM (
SELECT TOP (1) [t1].[AddressID] FROM [PersonAddress] AS [t1]
WHERE ([t1].[Index] = 1) AND ([t1].[PersonID] = [t0].[ID])
) AS [t2]
INNER JOIN [Address] AS [t3] ON [t3].[ID] = [t2].[AddressID]
) AS [Street1], (
SELECT [t6].[Suburb]
FROM (
SELECT TOP (1) [t4].[AddressID] FROM [PersonAddress] AS [t4]
WHERE ([t4].[Index] = 1) AND ([t4].[PersonID] = [t0].[ID])
) AS [t5]
INNER JOIN [Address] AS [t6] ON [t6].[ID] = [t5].[AddressID]
) AS [Suburb1], (
SELECT [t9].[Country]
FROM (
SELECT TOP (1) [t7].[AddressID] FROM [PersonAddress] AS [t7]
WHERE ([t7].[Index] = 1) AND ([t7].[PersonID] = [t0].[ID])
) AS [t8]
INNER JOIN [Address] AS [t9] ON [t9].[ID] = [t8].[AddressID]
) AS [Country1], (
SELECT [t12].[Street]
FROM (
SELECT TOP (1) [t10].[AddressID] FROM [PersonAddress] AS [t10]
WHERE ([t10].[Index] = 2) AND ([t10].[PersonID] = [t0].[ID])
) AS [t11]
INNER JOIN [Address] AS [t12] ON [t12].[ID] = [t11].[AddressID]
) AS [Street2], (
SELECT [t15].[Suburb]
FROM (
SELECT TOP (1) [t13].[AddressID] FROM [PersonAddress] AS [t13]
WHERE ([t13].[Index] = 2) AND ([t13].[PersonID] = [t0].[ID])
) AS [t14]
INNER JOIN [Address] AS [t15] ON [t15].[ID] = [t14].[AddressID]
) AS [Suburb2], (
SELECT [t18].[Country]
FROM (
SELECT TOP (1) [t16].[AddressID] FROM [PersonAddress] AS [t16]
WHERE ([t16].[Index] = 2) AND ([t16].[PersonID] = [t0].[ID])
) AS [t17]
INNER JOIN [Address] AS [t18] ON [t18].[ID] = [t17].[AddressID]
) AS [Country2]
FROM [Person] AS [t0]
Hoo boy, that’s horrible SQL! Notice how it’s doing a whole table join for every column? Imagine how that query would scale the more columns you had in your LINQ query! Epic fail.
Entity Framework (v4) fares much better, writing a ugly duckling query that is actually beautiful inside, performing at around the same speed as the target SQL (0.0172):
SELECT [Extent1].[ID] AS [ID], [Extent1].[Name] AS [Name], [Extent3].[Street] AS [Street],
[Extent3].[Suburb] AS [Suburb], [Extent3].[Country] AS [Country], [Extent5].[Street] AS [Street1],
[Extent5].[Suburb] AS [Suburb1], [Extent5].[Country] AS [Country1]
FROM [dbo].[Person] AS [Extent1]
OUTER APPLY (
SELECT TOP (1) [Extent2].[PersonID] AS [PersonID], [Extent2].[AddressID] AS [AddressID],
[Extent2].[Index] AS [Index]
FROM [dbo].[PersonAddress] AS [Extent2]
WHERE ([Extent1].[ID] = [Extent2].[PersonID]) AND (1 = [Extent2].[Index]) ) AS [Element1]
LEFT OUTER JOIN [dbo].[Address] AS [Extent3] ON [Element1].[AddressID] = [Extent3].[ID]
OUTER APPLY (
SELECT TOP (1) [Extent4].[PersonID] AS [PersonID], [Extent4].[AddressID] AS [AddressID],
[Extent4].[Index] AS [Index]
FROM [dbo].[PersonAddress] AS [Extent4]
WHERE ([Extent1].[ID] = [Extent4].[PersonID]) AND (2 = [Extent4].[Index]) ) AS [Element2]
LEFT OUTER JOIN [dbo].[Address] AS [Extent5] ON [Element2].[AddressID] = [Extent5].[ID]
So, if we’re stuck using LINQ to SQL and can’t jump ship to the more mature Entity Framework, how can we manipulate the LINQ to force it to write better SQL? Let’s try putting the Index predicate (ie pa => pa.Index == 1) into the join instead:
from person in context.Persons
join pa in context.PersonAddresses on new { person.ID, Index = 1 } equals new { ID = pa.PersonID, pa.Index } into pa1s
join pa in context.PersonAddresses on new { person.ID, Index = 2 } equals new { ID = pa.PersonID, pa.Index } into pa2s
from pa1 in pa1s.DefaultIfEmpty()
from pa2 in pa2s.DefaultIfEmpty()
let firstAddress = pa1.Address
let secondAddress = pa2.Address
select new
{
Name = person.Name,
Street1 = firstAddress.Street,
Suburb1 = firstAddress.Suburb,
Country1 = firstAddress.Country,
Street2 = secondAddress.Street,
Suburb2 = secondAddress.Suburb,
Country2 = secondAddress.Country,
}
This causes LINQ to SQL (and Entity Framework) to generate exactly the SQL we were originally aiming for! Notice the use of DefaultIfEmpty to turn the joins into left outer joins (remember that joins in LINQ are inner joins).
At this point you may be thinking “I’ll just use Entity Framework because it seems like I can trust it to write good SQL for me”. Hold your horses my friend; let’s modify the above query just slightly and get rid of those let statements, inlining the navigation through PeopleAddress’s Address property. That’s just navigating through a many to one relation, that shouldn’t cause any problems, right?
from person in context.Persons
join pa in context.PersonAddresses on new { person.ID, Index = 1 } equals new { ID = pa.PersonID, pa.Index } into pa1s
join pa in context.PersonAddresses on new { person.ID, Index = 2 } equals new { ID = pa.PersonID, pa.Index } into pa2s
from pa1 in pa1s.DefaultIfEmpty()
from pa2 in pa2s.DefaultIfEmpty()
select new
{
Name = person.Name,
Street1 = pa1.Address.Street,
Suburb1 = pa1.Address.Suburb,
Country1 = pa1.Address.Country,
Street2 = pa2.Address.Street,
Suburb2 = pa2.Address.Suburb,
Country2 = pa2.Address.Country,
}
Wrong! Now Entity Framework is doing that retarded table join-per-column thing (the query cost is 0.0312):
SELECT [Extent1].[ID] AS [ID], [Extent1].[Name] AS [Name], [Extent4].[Street] AS [Street],
[Extent5].[Suburb] AS [Suburb], [Extent6].[Country] AS [Country], [Extent7].[Street] AS [Street1],
[Extent8].[Suburb] AS [Suburb1], [Extent9].[Country] AS [Country1]
FROM [dbo].[Person] AS [Extent1]
LEFT OUTER JOIN [dbo].[PersonAddress] AS [Extent2] ON ([Extent1].[ID] = [Extent2].[PersonID]) AND (1 = [Extent2].[Index])
LEFT OUTER JOIN [dbo].[PersonAddress] AS [Extent3] ON ([Extent1].[ID] = [Extent3].[PersonID]) AND (2 = [Extent3].[Index])
LEFT OUTER JOIN [dbo].[Address] AS [Extent4] ON [Extent2].[AddressID] = [Extent4].[ID]
LEFT OUTER JOIN [dbo].[Address] AS [Extent5] ON [Extent2].[AddressID] = [Extent5].[ID]
LEFT OUTER JOIN [dbo].[Address] AS [Extent6] ON [Extent2].[AddressID] = [Extent6].[ID]
LEFT OUTER JOIN [dbo].[Address] AS [Extent7] ON [Extent3].[AddressID] = [Extent7].[ID]
LEFT OUTER JOIN [dbo].[Address] AS [Extent8] ON [Extent3].[AddressID] = [Extent8].[ID]
LEFT OUTER JOIN [dbo].[Address] AS [Extent9] ON [Extent3].[AddressID] = [Extent9].[ID]
Incidentally, if you put that query through LINQ to SQL, you’ll find it can deal with the inlined navigation properties and it still generates the correct query (sigh!).
So what’s the lesson here? The lesson is that you must always keep a very close eye on what SQL your LINQ providers are writing for you. A tool like LINQPad may be of some use, as you can write your queries in it and it’ll show you the generated SQL. Although Entity Framework does a better job with SQL generation than LINQ to SQL, as evidenced by it being able to handle our first, more intuitive, LINQ query, it’s still fairly easy to trip it up and get it to write badly performing SQL, so you still must keep your eye on it.
Comments (4)
Submit Comment | Comments RSS Feed

Simon Raik-Allen
July 20, 2011 10:11 AM
Nice post Daniel. I tend to find myself falling back to writing manual SQL for basically anything of importance (i.e., pulls lots of data or is called often).
What is your guideline for when to intervene with hand-crafted queries?

@Simon: Short answer: it depends. :)
Long answer: It depends (ha!) just how much pain LINQ is giving you, and how difficult it is to fit SQL into your application. Entity Framework lessens the pain as the LINQ query provider is better. L2S and EF both support compiled queries, so you can reduce the performance impact of using LINQ. At the end of the day, however, if you simply can't get LINQ to generate reasonably performing SQL (note that I didn't say "neat" SQL; who cares what it looks like so long as it performs acceptably) you've always got the option of hooking stored procedures into either L2S or EF. My experience with LINQ so far is that you can almost always get it to write decent SQL... with some tweaks to the LINQ. And as you discover and learn these tweaks, your productivity in LINQ increases. L2S is harder to get right, as it'll happily do stupid stuff like N+1 queries generated from your one LINQ query. EF won't do that, which helps immensely.
Simon Raik-Allen
July 21, 2011 1:41 AM
On the flip side, convoluting your source to effect the output could degrade its maintainability. Not that that will always be the case, but its another thing to add to the balancing act. Damned if you do, damned if you don't :-)
A Linq2Sql cheat sheet for these tips would be cool.
Thanks, again.
@Simon: Yes, convoluting your LINQ can degrade your maintainability, however, you might be able to improve the maintainability of the LINQ queries where you've done weird esoteric hacks (such as the ones discussed in the previous blog post I linked at the top of this one) by using an expression rewriter like the one I discussed here:
http://www.digitallycreated.net/Blog/66/sweeping-yucky-linq-queries-under-the-rug-with-expression-tree-rewriting
However, with respect to this blog post, I wouldn't consider the alternative query structure proposed here unmaintainable. In fact, it looks very much like SQL! Your only issue is communicating why the query has been written that way and not some other way, which a process of LINQ best practices education amongst your developers would help with.