
Only showing posts tagged with "Performance"
More Lessons from the LINQ Database Query Performance Land
July 19, 2011 2:00 PM by Daniel Chambers (last modified on July 19, 2011 2:20 PM)
Writing LINQ against databases using providers like LINQ to SQL and Entity Framework is harder than it first appears. There are many different ways to write the same query in LINQ and many of them cause LINQ providers to generate really horrible SQL. LINQ to SQL is quite the offender in this area but, as we’ll see, Entity Framework can write bad SQL too. The trick is knowing how to write LINQ that doesn’t result in horribly slow queries, so in this blog post we’ll look at an interesting table joining scenario where different LINQ queries produce SQL of vastly different quality.
Here’s the database schema:
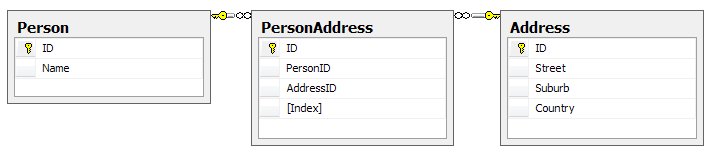
Yes, this may not be the best database design as you could arguably merge PersonAddress and Address, but it’ll do for an example; it’s the query structure we’re more interested in rather than the contents of the tables. One thing to note is that the Index column on PersonAddress is there to number the addresses associated with the person, ie Address 1, Address 2. There cannot be two PersonAddresses for the same person with the same Index. Our entity classes map exactly to these tables.
Let’s say we want to write a query for reporting purposes that flattens this structure out like so:

Optimally, we’d like the LINQ query to write this SQL for us (or at least SQL that performs as well as this; this has a cost of 0.0172):
SELECT p.Name, a1.Street AS 'Street 1', a1.Suburb AS 'Suburb 1', a1.Country AS 'Country 1',
a2.Street AS 'Street 2', a2.Suburb AS 'Suburb 2', a2.Country AS 'Country 2'
FROM Person p
LEFT OUTER JOIN PersonAddress pa1 on p.ID = pa1.PersonID AND pa1.[Index] = 1
LEFT OUTER JOIN PersonAddress pa2 on p.ID = pa2.PersonID AND pa2.[Index] = 2
LEFT OUTER JOIN [Address] a1 on a1.ID = pa1.AddressID
LEFT OUTER JOIN [Address] a2 on a2.ID = pa2.AddressID
One way of doing this using LINQ, and taking advantage of navigation properties on the entity classes, might be this:
from person in context.People
let firstAddress = person.PersonAddresses.FirstOrDefault(pa => pa.Index == 1).Address
let secondAddress = person.PersonAddresses.FirstOrDefault(pa => pa.Index == 2).Address
select new
{
Name = person.Name,
Street1 = firstAddress.Street,
Suburb1 = firstAddress.Suburb,
Country1 = firstAddress.Country,
Street2 = secondAddress.Street,
Suburb2 = secondAddress.Suburb,
Country2 = secondAddress.Country,
}
However, using LINQ to SQL, the following SQL is generated (and its cost is 0.0458, which is nearly three times the cost of the SQL we’re aiming for):
SELECT [t0].[Name], (
SELECT [t3].[Street]
FROM (
SELECT TOP (1) [t1].[AddressID] FROM [PersonAddress] AS [t1]
WHERE ([t1].[Index] = 1) AND ([t1].[PersonID] = [t0].[ID])
) AS [t2]
INNER JOIN [Address] AS [t3] ON [t3].[ID] = [t2].[AddressID]
) AS [Street1], (
SELECT [t6].[Suburb]
FROM (
SELECT TOP (1) [t4].[AddressID] FROM [PersonAddress] AS [t4]
WHERE ([t4].[Index] = 1) AND ([t4].[PersonID] = [t0].[ID])
) AS [t5]
INNER JOIN [Address] AS [t6] ON [t6].[ID] = [t5].[AddressID]
) AS [Suburb1], (
SELECT [t9].[Country]
FROM (
SELECT TOP (1) [t7].[AddressID] FROM [PersonAddress] AS [t7]
WHERE ([t7].[Index] = 1) AND ([t7].[PersonID] = [t0].[ID])
) AS [t8]
INNER JOIN [Address] AS [t9] ON [t9].[ID] = [t8].[AddressID]
) AS [Country1], (
SELECT [t12].[Street]
FROM (
SELECT TOP (1) [t10].[AddressID] FROM [PersonAddress] AS [t10]
WHERE ([t10].[Index] = 2) AND ([t10].[PersonID] = [t0].[ID])
) AS [t11]
INNER JOIN [Address] AS [t12] ON [t12].[ID] = [t11].[AddressID]
) AS [Street2], (
SELECT [t15].[Suburb]
FROM (
SELECT TOP (1) [t13].[AddressID] FROM [PersonAddress] AS [t13]
WHERE ([t13].[Index] = 2) AND ([t13].[PersonID] = [t0].[ID])
) AS [t14]
INNER JOIN [Address] AS [t15] ON [t15].[ID] = [t14].[AddressID]
) AS [Suburb2], (
SELECT [t18].[Country]
FROM (
SELECT TOP (1) [t16].[AddressID] FROM [PersonAddress] AS [t16]
WHERE ([t16].[Index] = 2) AND ([t16].[PersonID] = [t0].[ID])
) AS [t17]
INNER JOIN [Address] AS [t18] ON [t18].[ID] = [t17].[AddressID]
) AS [Country2]
FROM [Person] AS [t0]
Hoo boy, that’s horrible SQL! Notice how it’s doing a whole table join for every column? Imagine how that query would scale the more columns you had in your LINQ query! Epic fail.
Entity Framework (v4) fares much better, writing a ugly duckling query that is actually beautiful inside, performing at around the same speed as the target SQL (0.0172):
SELECT [Extent1].[ID] AS [ID], [Extent1].[Name] AS [Name], [Extent3].[Street] AS [Street],
[Extent3].[Suburb] AS [Suburb], [Extent3].[Country] AS [Country], [Extent5].[Street] AS [Street1],
[Extent5].[Suburb] AS [Suburb1], [Extent5].[Country] AS [Country1]
FROM [dbo].[Person] AS [Extent1]
OUTER APPLY (
SELECT TOP (1) [Extent2].[PersonID] AS [PersonID], [Extent2].[AddressID] AS [AddressID],
[Extent2].[Index] AS [Index]
FROM [dbo].[PersonAddress] AS [Extent2]
WHERE ([Extent1].[ID] = [Extent2].[PersonID]) AND (1 = [Extent2].[Index]) ) AS [Element1]
LEFT OUTER JOIN [dbo].[Address] AS [Extent3] ON [Element1].[AddressID] = [Extent3].[ID]
OUTER APPLY (
SELECT TOP (1) [Extent4].[PersonID] AS [PersonID], [Extent4].[AddressID] AS [AddressID],
[Extent4].[Index] AS [Index]
FROM [dbo].[PersonAddress] AS [Extent4]
WHERE ([Extent1].[ID] = [Extent4].[PersonID]) AND (2 = [Extent4].[Index]) ) AS [Element2]
LEFT OUTER JOIN [dbo].[Address] AS [Extent5] ON [Element2].[AddressID] = [Extent5].[ID]
So, if we’re stuck using LINQ to SQL and can’t jump ship to the more mature Entity Framework, how can we manipulate the LINQ to force it to write better SQL? Let’s try putting the Index predicate (ie pa => pa.Index == 1) into the join instead:
from person in context.Persons
join pa in context.PersonAddresses on new { person.ID, Index = 1 } equals new { ID = pa.PersonID, pa.Index } into pa1s
join pa in context.PersonAddresses on new { person.ID, Index = 2 } equals new { ID = pa.PersonID, pa.Index } into pa2s
from pa1 in pa1s.DefaultIfEmpty()
from pa2 in pa2s.DefaultIfEmpty()
let firstAddress = pa1.Address
let secondAddress = pa2.Address
select new
{
Name = person.Name,
Street1 = firstAddress.Street,
Suburb1 = firstAddress.Suburb,
Country1 = firstAddress.Country,
Street2 = secondAddress.Street,
Suburb2 = secondAddress.Suburb,
Country2 = secondAddress.Country,
}
This causes LINQ to SQL (and Entity Framework) to generate exactly the SQL we were originally aiming for! Notice the use of DefaultIfEmpty to turn the joins into left outer joins (remember that joins in LINQ are inner joins).
At this point you may be thinking “I’ll just use Entity Framework because it seems like I can trust it to write good SQL for me”. Hold your horses my friend; let’s modify the above query just slightly and get rid of those let statements, inlining the navigation through PeopleAddress’s Address property. That’s just navigating through a many to one relation, that shouldn’t cause any problems, right?
from person in context.Persons
join pa in context.PersonAddresses on new { person.ID, Index = 1 } equals new { ID = pa.PersonID, pa.Index } into pa1s
join pa in context.PersonAddresses on new { person.ID, Index = 2 } equals new { ID = pa.PersonID, pa.Index } into pa2s
from pa1 in pa1s.DefaultIfEmpty()
from pa2 in pa2s.DefaultIfEmpty()
select new
{
Name = person.Name,
Street1 = pa1.Address.Street,
Suburb1 = pa1.Address.Suburb,
Country1 = pa1.Address.Country,
Street2 = pa2.Address.Street,
Suburb2 = pa2.Address.Suburb,
Country2 = pa2.Address.Country,
}
Wrong! Now Entity Framework is doing that retarded table join-per-column thing (the query cost is 0.0312):
SELECT [Extent1].[ID] AS [ID], [Extent1].[Name] AS [Name], [Extent4].[Street] AS [Street],
[Extent5].[Suburb] AS [Suburb], [Extent6].[Country] AS [Country], [Extent7].[Street] AS [Street1],
[Extent8].[Suburb] AS [Suburb1], [Extent9].[Country] AS [Country1]
FROM [dbo].[Person] AS [Extent1]
LEFT OUTER JOIN [dbo].[PersonAddress] AS [Extent2] ON ([Extent1].[ID] = [Extent2].[PersonID]) AND (1 = [Extent2].[Index])
LEFT OUTER JOIN [dbo].[PersonAddress] AS [Extent3] ON ([Extent1].[ID] = [Extent3].[PersonID]) AND (2 = [Extent3].[Index])
LEFT OUTER JOIN [dbo].[Address] AS [Extent4] ON [Extent2].[AddressID] = [Extent4].[ID]
LEFT OUTER JOIN [dbo].[Address] AS [Extent5] ON [Extent2].[AddressID] = [Extent5].[ID]
LEFT OUTER JOIN [dbo].[Address] AS [Extent6] ON [Extent2].[AddressID] = [Extent6].[ID]
LEFT OUTER JOIN [dbo].[Address] AS [Extent7] ON [Extent3].[AddressID] = [Extent7].[ID]
LEFT OUTER JOIN [dbo].[Address] AS [Extent8] ON [Extent3].[AddressID] = [Extent8].[ID]
LEFT OUTER JOIN [dbo].[Address] AS [Extent9] ON [Extent3].[AddressID] = [Extent9].[ID]
Incidentally, if you put that query through LINQ to SQL, you’ll find it can deal with the inlined navigation properties and it still generates the correct query (sigh!).
So what’s the lesson here? The lesson is that you must always keep a very close eye on what SQL your LINQ providers are writing for you. A tool like LINQPad may be of some use, as you can write your queries in it and it’ll show you the generated SQL. Although Entity Framework does a better job with SQL generation than LINQ to SQL, as evidenced by it being able to handle our first, more intuitive, LINQ query, it’s still fairly easy to trip it up and get it to write badly performing SQL, so you still must keep your eye on it.
Working Around Performance Issues in LINQ to SQL and SQL CE 3.5
April 25, 2011 5:17 PM by Daniel Chambers (last modified on May 02, 2011 2:26 PM)
Recently I’ve been optimising LINQ to SQL queries running against an SQL CE 3.5 database in order to stop them taking over 5 minutes to execute and bringing them down to only a few seconds. In this post I’m going to go into two of the biggest offenders I’ve seen so far in terms of killing query performance. Credit must go to my fellow Readifarian Colin Savage with whom I worked to discover and find solutions for the offending LINQ query expressions.
In this post, I’m going to be using the following demonstration LINQ to SQL classes. Note that these are just demo classes and aren’t recommended practice or even fully fleshed out. Note that Game.DeveloperID has an index against it in the database.
[Table(Name = "Developer")]
public class Developer
{
[Column(DbType = "int NOT NULL IDENTITY", IsPrimaryKey=true, IsDbGenerated=true)]
public int ID { get; set; }
[Column(DbType = "nvarchar(50) NOT NULL")]
public string Name { get; set; }
}
[Table(Name = "Game")]
public class Game
{
[Column(DbType = "int NOT NULL IDENTITY", IsPrimaryKey=true, IsDbGenerated=true)]
public int ID { get; set; }
[Column(DbType = "nvarchar(50) NOT NULL")]
public string Name { get; set; }
[Column(DbType = "int NOT NULL")]
public int DeveloperID { get; set; }
[Column(DbType = "int NOT NULL")]
public int Ordinal { get; set; }
}
Outer Joining and Null Testing Entities
The first performance killer Colin and I ran into is where you’re testing whether an outer joined entity is null. Here’s a query that includes the performance killer expression:
var query = from d in context.GetTable<Developer>()
join g in context.GetTable<Game>()
on d.ID equals g.DeveloperID into tempG
from g in tempG.DefaultIfEmpty()
select new
{
d,
//Inefficient
Name = g != null ? g.Name : String.Empty,
};
The above query is doing a left outer join of Game against Developer, and in the case that the developer doesn’t have any games, it’s setting the Name property of the anonymous projection object to String.Empty. Seems like a pretty reasonable query, right?
Wrong. In SQL CE, this is the SQL generated and the query plan created:
SELECT [t0].[ID], [t0].[Name],
(CASE
WHEN [t2].[test] IS NOT NULL THEN [t2].[Name]
ELSE CONVERT(NVarChar(50),'')
END) AS [Name2]
FROM [Developer] AS [t0]
LEFT OUTER JOIN (
SELECT 1 AS [test], [t1].[Name], [t1].[DeveloperID]
FROM [Game] AS [t1]
) AS [t2] ON [t0].[ID] = [t2].[DeveloperID]

Inefficient join between two table scans on SQL CE 3.5
The problem is that the “SELECT 1 AS [test]” subquery in the SQL is causing SQL CE to do a join between two table scans, which on tables with lots of data is very very slow. Thankfully for those using real SQL Server (I tested on 2008 R2), it seems to be able to deal with this query form and generates an efficient query plan, as shown below.

Efficient join between two clustered index scans on SQL Server 2008 R2
So, what can we do to eliminate that subquery from the SQL? Well, we’re causing that subquery by performing a null test against the entity object in the LINQ expression (LINQ to SQL looks at the [test] column to see if there is a joined entity there; if it’s 1, there is, if it’s NULL, there isn’t). So how about this query instead?
var query = from d in context.GetTable<Developer>()
join g in context.GetTable<Game>()
on d.ID equals g.DeveloperID into tempG
from g in tempG.DefaultIfEmpty()
select new
{
d,
//Efficient
Name = g.ID != 0 ? g.Name : String.Empty,
};
Success! This generates the following SQL and query plan against SQL CE 3.5:
SELECT [t0].[ID], [t0].[Name],
(CASE
WHEN [t1].[ID] <> 0 THEN CONVERT(NVarChar(50),[t1].[Name])
ELSE NULL
END) AS [Name2]
FROM [Developer] AS [t0]
LEFT OUTER JOIN [Game] AS [t1] ON [t0].[ID] = [t1].[DeveloperID]

Efficient join between a table scan and an index seek on SQL CE 3.5
The subquery has been removed from the SQL and the query plan reflects this; it now uses an index seek instead of a second table scan in order to do the join. This is much faster!
Okay, that seems like a simple fix. So when we use it like below, putting g.Name into another object, it should keep working correctly, right?
var query = from d in context.GetTable<Developer>()
join g in context.GetTable<Game>()
on d.ID equals g.DeveloperID into tempG
from g in tempG.DefaultIfEmpty()
select new
{
d,
//Broken
Name = g.ID != 0 ? new Wrap { Str = g.Name } : null
};
Unfortunately, no. You may get an InvalidOperationException at runtime (depending on the data in your DB) with the confusing message “The null value cannot be assigned to a member with type System.Boolean which is a non-nullable value type.”
If we look at the SQL generated by this LINQ query and the data returned from the DB, we can see what’s causing this problem:
SELECT [t0].[ID], [t0].[Name],
(CASE
WHEN [t1].[ID] <> 0 THEN 1
WHEN NOT ([t1].[ID] <> 0) THEN 0
ELSE NULL
END) AS [value], [t1].[Name] AS [Str]
FROM [Developer] AS [t0]
LEFT OUTER JOIN [Game] AS [t1] ON [t0].[ID] = [t1].[DeveloperID]

The data returned by the broken query
It’s probably a fair to make the assumption that LINQ to SQL is using the [value] column internally to evaluate the “g.ID != 0” part of the LINQ query, but you’ll notice that in the data the value is NULL for one of the rows. This seems to be what is causing the “can’t assign a null to a bool” error we’re getting. I think this is a bug in LINQ to SQL, because as far as I can tell as this is pretty unintuitive behaviour. Note that this SQL query form, that causes this problem with its CASE, WHEN, WHEN, ELSE expression, is only generated when we project the results into another object, not when we just project the results straight into the main projection object. I don’t know why this is.
So how can we work around this? Prepare to vomit just a little bit, up in the back of your mouth:
var query = from d in context.GetTable<Developer>()
join g in context.GetTable<Game>()
on d.ID equals g.DeveloperID into tempG
from g in tempG.DefaultIfEmpty()
select new
{
d,
//Fixed! (WTF??)
Name = (int?)g.ID != null ? new Wrap { Str = g.Name } : null
};
Mmm, tasty! :S Yes, that C# doesn’t even make sense and a good tool like ReSharper would tell you to remove that pointless int? cast, because ID is already an int and casting it to an int? and checking for null is entirely pointless. But this query form forces LINQ to SQL to generate the SQL we want:
SELECT [t0].[ID], [t0].[Name],
(CASE
WHEN ([t1].[ID]) IS NOT NULL THEN 1
ELSE 0
END) AS [value], [t1].[Name] AS [Str]
FROM [Developer] AS [t0]
LEFT OUTER JOIN [Game] AS [t1] ON [t0].[ID] = [t1].[DeveloperID]

The data returned by the fixed query
Note that the query now returns the expected 0 value instead of NULL in the last row.
Outer Joining and Projecting into an Object Constructor
The other large performance killer Colin and I ran into is where you project into an object constructor. Here’s an example:
var query = from d in context.GetTable<Developer>()
join g in context.GetTable<Game>()
on d.ID equals g.DeveloperID into tempG
from g in tempG.DefaultIfEmpty()
select new
{
d,
//Inefficient
Name = (int?)g.ID != null ? new Wrap(g) : null
};
In the above query we’re passing the whole Game object into Wrap’s constructor, where it’ll copy the Game’s properties to its properties. This makes for neater queries, instead of having a massive object initialiser block where you set all the properties on Wrap with properties from Game. Too bad it reintroduces our little subquery issue back into the SQL:
SELECT [t0].[ID], [t0].[Name],
(CASE
WHEN ([t2].[ID]) IS NOT NULL THEN 1
ELSE 0
END) AS [value], [t2].[test], [t2].[ID] AS [ID2], [t2].[Name] AS [Name2], [t2].[DeveloperID], [t2].[Ordinal]
FROM [Developer] AS [t0]
LEFT OUTER JOIN (
SELECT 1 AS [test], [t1].[ID], [t1].[Name], [t1].[DeveloperID], [t1].[Ordinal]
FROM [Game] AS [t1]
) AS [t2] ON [t0].[ID] = [t2].[DeveloperID]
Unfortunately, the only way to get rid of the subquery again is to ditch the constructor and manually initialise the object with an object initialiser, making your queries much longer and noisy when there are a lot of properties:
var query = from d in context.GetTable<Developer>()
join g in context.GetTable<Game>()
on d.ID equals g.DeveloperID into tempG
from g in tempG.DefaultIfEmpty()
select new
{
d,
//Efficient
Name = (int?)g.ID != null ? new Wrap { Str = g.Name } : null
};
This gives us back our efficient (on SQL CE 3.5) SQL:
SELECT [t0].[ID], [t0].[Name],
(CASE
WHEN ([t1].[ID]) IS NOT NULL THEN 1
ELSE 0
END) AS [value], [t1].[Name] AS [Str]
FROM [Developer] AS [t0]
LEFT OUTER JOIN [Game] AS [t1] ON [t0].[ID] = [t1].[DeveloperID]
Conclusion
For those using LINQ to SQL against real SQL Server, these LINQ contortions are unnecessary to get your performance as real SQL Server is able to make efficient query plans for the form of query that LINQ to SQL creates. However, SQL CE 3.5 can’t deal with these queries and so you need to munge your LINQ queries a bit to get them to perform, which is frustrating. Heading into the future, this won’t be a problem (hopefully) because SQL CE 4 doesn’t support LINQ to SQL and hopefully Entity Framework 4 doesn’t write queries like this (or maybe SQL CE 4 can just deal with it properly). For those on that software stack, it’s probably worth checking out what EF and SQL CE 4 is doing under the covers, as these problems highlight the need for software developers to watch what their LINQ providers are writing for them under the covers to make sure it’s performant.
Edit: For a way to help clean up the verbose hacked up LINQ queries that you end up with when working around these performance problems, check out this post.