
Only showing posts tagged with "Lambdas"
Sweeping Yucky LINQ Queries Under the Rug with Expression Tree Rewriting
May 02, 2011 2:06 PM by Daniel Chambers (last modified on May 03, 2011 6:43 AM)
In my last post, I explained some workarounds that you could hack into your LINQ queries to get them to perform well when using LINQ to SQL and SQL CE 3.5. Although those workarounds do help fix performance issues, they can make your LINQ query code very verbose and noisy. In places where you’d simply call a constructor and pass an entity object in, you now have to use an object initialiser and copy the properties manually. What if there are 10 properties (or more!) on that class? You get a lot of inline code. What if you use it across 10 queries and you later want to add a property to that class? You have to find and change it in 10 places. Did somebody mention code smell?
In order to work around this issue, I’ve whipped up a small amount of code that allows you to centralise these repeated chunks of query code, but unlike the normal (and still recommended, if you don’t have these performance issues) technique of putting the code in a method/constructor, this doesn’t trigger these performance issues. How? Instead of the query calling into an external method to execute your query snippet, my code takes your query snippet and inlines it directly into the LINQ query’s expression tree. (If you’re rusty on expression trees, try reading this post, which deals with some basic expression trees stuff.) I’ve called this code the ExpressionTreeRewriter.
The Rewriter in Action
Let’s set up a little (and very contrived) scenario and then clean up the mess using the rewriter. Imagine we had this entity and this DTO:
public class PersonEntity
{
public int ID { get; set; }
public string FirstName { get; set; }
public string LastName { get; set; }
}
public class PersonDto
{
public int EntityID { get; set; }
public string GivenName { get; set; }
public string Surname { get; set; }
}
Then imagine this nasty query (if it’s not nasty enough for you, add 10 more properties to PersonEntity and PersonDto in your head):
IQueryable<PersonDto> people = from person in context.People
select new PersonDto
{
EntityID = person.ID,
GivenName = person.FirstName,
Surname = person.LastName,
};
Normally, you’d just put those property assignments in a PersonDto constructor that takes a PersonEntity and then call that constructor in the query. Unfortunately, we can’t do that for performance reasons. So how can we centralise those property assignments, but keep our object initialiser? I’m glad you asked!
First, let’s add some stuff to PersonDto:
public class PersonDto
{
...
public static Expression<Func<PersonEntity,PersonDto>> ToPersonDtoExpression
{
get
{
return person => new PersonDto
{
EntityID = person.ID,
GivenName = person.FirstName,
Surname = person.LastName,
};
}
}
[RewriteUsingLambdaProperty(typeof(PersonDto), "ToPersonDtoExpression")]
public static PersonDto ToPersonDto(PersonEntity person)
{
throw new InvalidOperationException("This method is a marker method and must be rewritten out.");
}
}
Now let’s rewrite the query:
IQueryable<PersonDto> people = (from person in context.People
select PersonDto.ToPersonDto(person)).Rewrite();
Okay, admittedly it’s still not as nice as just calling a constructor, but unfortunately our hands are tied in that respect. However, you’ll notice that we’ve centralised that object initialiser snippet into the ToPersonDtoExpression property and somehow we’re using that by calling ToPersonDto in our query.
So how does this all work? The PersonDto.ToPersonDto static method is what I’ve dubbed a “marker method”. As you can see, it does nothing at all, simply throwing an exception to help with debugging. The call to this method is incorporated into the expression tree constructed for the query (stored in IQueryable<T>.Expression). This is what that expression tree looks like:

The expression tree before being rewritten
When you call the Rewrite extension method on your IQueryable, it recurs through this expression tree looking for MethodCallExpressions that represent calls to marker methods that it can rewrite. Notice that the ToPersonDto method has the RewriteUsingLambdaPropertyAttribute applied to it? This tells the rewriter that it should replace that method call with an inlined copy of the LambdaExpression returned by the specified static property. Once this is done, the expression tree looks like this:
")
The expression tree after being rewritten (click to enlarge)
Notice that the LambdaExpression’s Body (which used to be the MethodCallExpression of the marker method) has been replaced with the expression tree for the object initialiser.
Something to note: the method signature of marker method and that of the delegate type passed to Expression<T> on your static property must be identical. So if your marker method takes two ClassAs and returns a ClassB, your static property must be of type Expression<Func<ClassA,ClassA,ClassB>> (or some delegate equivalent to the Func<T1,T2,TResult> delegate). If they don’t match, you will get an exception at runtime.
Rewriter Design

Expression Tree Rewriter Design Diagram
The ExpressionTreeRewriter is the class that implements the .Rewrite() extension method. It searches through the expression tree for called methods that have a RewriterMarkerMethodAttribute on them. RewriterMarkerMethodAttribute is an abstract class, one implementation of which you have already seen. The ExpressionTreeRewriter uses the attribute to create an object implementing IExpressionRewriter which it uses to rewrite the MethodCallExpression it found.
The RewriteUsingLambdaPropertyAttribute creates a LambdaInlinerRewriter properly configured to inline the LambdaExpression returned from your static property. The LambdaInlinerRewriter is called by the ExpressionTreeRewriter to rewrite the marker MethodCallExpression and replace it with the body of the LambdaExpression returned by your static property.
The other marker attribute, RewriteUsingRewriterClassAttribute, allows you to specify a class that implements IExpressionRewriter which will be returned to the rewriter when it wants to rewrite that marker method. Using this attribute gives you low level control over the rewriting as you can create classes that write expression trees by hand.
The EntityNullTestRewriter is one such class. It takes a query with the nasty nullable int performance hack:
IQueryable<IntEntity> queryable = entities.AsQueryable()
.Where(e => (int?)e.ID != null)
.Rewrite();
and allows you to sweep that hacky code under the rug, so to speak:
IQueryable<IntEntity> queryable = entities.AsQueryable()
.Where(e => RewriterMarkers.EntityNullTest(e.ID))
.Rewrite();
RewriterMarkers.EntityNullTest looks like this:
[RewriteUsingRewriterClass(typeof(EntityNullTestRewriter))]
public static bool EntityNullTest<T>(T entityPrimaryKey)
{
throw new InvalidOperationException("Should not be executed. Should be rewritten out of the expression tree.");
}
The advantage of EntityNullTest is that people can look at its documentation to see why it’s being used. A person new to the project, or who doesn’t know about the performance hacks, may refactor the int? cast away as it looks like pointless bad code. Using something like EntityNullTest prevents this from happening and also raises awareness of the performance issues.
Give Me The Code!
Enough chatter, you want the code don’t you? The ExpressionTreeRewriter is a part of the DigitallyCreated Utilities BCL library. However, at the time of writing (changeset 4d1274462543), the current release of DigitallyCreated Utilities doesn’t include it, so you’ll need to check out the code from the repository and compile it yourself (easy). The ExpressionTreeRewriter only supports .NET 4, as it uses the ExpressionVisitor class only available in .NET 4; so don’t accidentally use a revision from the .NET 3.5 branch and wonder why the rewriter is not there.
I will get around to making a proper official release of DigitallyCreated Utilities at some point; I’m slowly but surely writing the doco for all the new stuff that I’ve added, and also writing a proper build script that will automate the releases for me and hopefully create NuGet packages too.
Conclusion
The ExpressionTreeRewriter is not something you should just use willy-nilly. If you can get by without it by using constructors and method calls in your LINQ, please do so; your code will be much neater and more understandable. However, if you find yourself in a place like those of us fighting with LINQ to SQL and SQL CE 3.5 performance, a place where you really need to inline lambdas and rewrite your expression trees, please be my guest, download the code, and enjoy.
More Dynamic Queries using Expression Trees
February 09, 2011 2:42 PM by Daniel Chambers
In my first post on dynamic queries using expression trees, I explained how one could construct an expression tree manually that would take an array (for example, {10,12,14}) and turn it into a query like this:
tag => tag.ID == 10 || tag.ID == 12 || tag.ID == 14
A reader recently wrote to me and asked whether one could form a similar query that instead queried across multiple properties, like this:
tag => tag.ID == 10 || tag.ID == 12 || tag.Name == "C#" || tag.Name == "Expression Trees"
The short answer is “yes, you can”, however the long answer is “yes, but it takes a bit of doing”! In this blog post, I’ll detail how to write a utility method that allows you to create these sorts of queries for any number of properties on an object. (If you haven’t read the previous post, please read it now.)
Previously we had defined a method with this signature (I’ve renamed the “convertBetweenTypes” parameter to “memberAccessExpression”; the original name sucked, frankly; this is a clearer name):
public static Expression<Func<TValue, bool>> BuildOrExpressionTree<TValue, TCompareAgainst>(
IEnumerable<TCompareAgainst> wantedItems,
Expression<Func<TValue, TCompareAgainst>> memberAccessExpression)
Now that we want to query multiple properties, we’ll need to change this signature to something that allows you to pass multiple wantedItems lists and a memberAccessExpression for each of them.
public static Expression<Func<TValue, bool>> BuildOrExpressionTree<TValue>(
IEnumerable<Tuple<IEnumerable<object>, LambdaExpression>> wantedItemCollectionsAndMemberAccessExpressions)
Eeek! That’s a pretty massive new single parameter. What we’re now doing is passing in multiple Tuples (if you’re using .NET 3.5, make your own Tuple class), where the first component is the list of wanted items, and the second component is the member access expression. You’ll notice that a lot of the generic types have gone out the window and we’re passing IEnumerables of object and LambdaExpressions around; this is a price we’ll have to pay for having a more flexible method.
How would you call this monster method? Like this:
var wantedItemsAndMemberExprs = new List<Tuple<IEnumerable<object>, LambdaExpression>>
{
new Tuple<IEnumerable<object>, LambdaExpression>(new object[] {10, 12}, (Expression<Func<Tag, int>>)(t => t.ID)),
new Tuple<IEnumerable<object>, LambdaExpression>(new[] {"C#", "Expression Trees"}, (Expression<Func<Tag, string>>)(t => t.Name)),
};
Expression<Func<Tag, bool>> whereExpr = BuildOrExpressionTree<Tag>(wantedItemsAndMemberExprs);
Note having to explicitly specify “object[]” for the array of IDs; this is because, although you can now assign IEnumerable<ChildClass> to IEnumerable<ParentClass> (covariance) in C# 4, that only works for reference types. Value types are invariant, so you need to explicitly force int to be boxed as a reference type. Note also having to explicitly cast the member access lambda expressions; this is because the C# compiler won’t generate an expression tree for you unless it knows you explicitly want an Expression<T>; casting forces it to understand that you want an expression tree here and not just some anonymous delegate.
So how is the new BuildOrExpressionTree method implemented? Like this:
public static Expression<Func<TValue, bool>> BuildOrExpressionTree<TValue>(
IEnumerable<Tuple<IEnumerable<object>, LambdaExpression>> wantedItemCollectionsAndMemberAccessExpressions)
{
ParameterExpression inputParam = null;
Expression binaryExpressionTree = null;
if (wantedItemCollectionsAndMemberAccessExpressions.Any() == false)
throw new ArgumentException("wantedItemCollectionsAndMemberAccessExpressions may not be empty", "wantedItemCollectionsAndMemberAccessExpressions");
foreach (Tuple<IEnumerable<object>, LambdaExpression> tuple in wantedItemCollectionsAndMemberAccessExpressions)
{
IEnumerable<object> wantedItems = tuple.Item1;
LambdaExpression memberAccessExpr = tuple.Item2;
if (inputParam == null)
inputParam = memberAccessExpr.Parameters[0];
else
memberAccessExpr = new ParameterExpressionRewriter(memberAccessExpr.Parameters[0], inputParam).VisitAndConvert(memberAccessExpr, "BuildOrExpressionTree");
BuildBinaryOrTree(wantedItems, memberAccessExpr.Body, ref binaryExpressionTree);
}
return Expression.Lambda<Func<TValue, bool>>(binaryExpressionTree, new[] { inputParam });
}
As I explain this method, you may want to keep an eye on the expression tree diagram from the previous post, so you can visualise the expression tree structure easily. The method loops through each tuple that contains a wantedItems collection and a memberAccessExpression, and progressively builds an expression tree from all the items in all the collections. You’ll notice within the foreach loop that the ParameterExpression from the first memberAccessExpression is kept and used to “rewrite” subsequent memberAccessExpressions. Each memberAccessExpr is a separate expression tree, each with its own ParameterExpression, but since we’re now using multiple of them and combining them all into a single expression tree that still takes a single parameter, we need to ensure that those expressions use a common ParameterExpression. We do this by implementing an ExpressionVisitor that rewrites the expression and replaces the ParameterExpression it uses with the one we want it to use.
{kind=link}
public class ParameterExpressionRewriter : ExpressionVisitor
{
private ParameterExpression _OldExpr;
private ParameterExpression _NewExpr;
public ParameterExpressionRewriter(ParameterExpression oldExpr, ParameterExpression newExpr)
{
_OldExpr = oldExpr;
_NewExpr = newExpr;
}
protected override Expression VisitParameter(ParameterExpression node)
{
if (node == _OldExpr)
return _NewExpr;
else
return base.VisitParameter(node);
}
}
The ExpressionVisitor uses the visitor pattern, so it recurses through an expression tree and calls different methods on the class depending on what node type it encounters and allows you to rewrite the tree by returning something different from the method. In the VisitParameter method above, we’re simply returning the new ParameterExpression when we encounter the old ParameterExpression in the tree. Note that ExpressionVisitor is new to .NET 4, so if you’re stuck in 3.5-land use this similar implementation instead. (For more information on modifying expression trees, see this MSDN page.)
Going back to the BuildOrExpressionTree method, we see the next thing we do is call the BuildBinaryOrTree method. Note that this method is slightly different to the implementation in the previous post, as I’ve changed it to be a faster iterative algorithm (rather than recursive) and it no longer is generic. The method should look pretty familiar:
private static void BuildBinaryOrTree(
IEnumerable<object> items,
Expression memberAccessExpr,
ref Expression expression)
{
foreach (object item in items)
{
ConstantExpression constant = Expression.Constant(item, item.GetType());
BinaryExpression comparison = Expression.Equal(memberAccessExpr, constant);
if (expression == null)
expression = comparison;
else
expression = Expression.OrElse(expression, comparison);
}
}
As you can see, for each iteration in the main BuildBinaryOrExpressionTree, the existing binary OR tree is fed back into the BuildBinaryOrTree method and extended with more nodes, except each different call uses items from a different collection and a different memberAccessExpression to extend the tree. Once all Tuples have been processed, the binary OR tree is bound together with its ParameterExpression and turned into the LambdaExpression we need for use in an IQueryable Where method. We can use it like this:
Expression<Func<Tag, bool>> whereExpr = BuildOrExpressionTree<Tag>(wantedItemsAndMemberExprs); IQueryable<Tag> tagQuery = tags.Where(whereExpr);
In conclusion, we see that wanting to query those additional properties required us to add a whole bunch more code in order to make it work. However, in the end, it does work and works quite well, although admittedly the method is a little awkward to use. This could be cleaned up by wrapping it in a “builder”-style class that simplifies the API a little, but I’ll leave that as an exercise to the reader.
Dynamic Queries in Entity Framework using Expression Trees
June 06, 2009 2:00 PM by Daniel Chambers (last modified on January 13, 2011 12:24 PM)
Most of the queries you do in your application are probably static queries. The parameters you set on the query probably change, but the actual query itself doesn't. That's why compiled queries are so cool, because you can pre-compile and reuse a query over and over again and just vary the parameters (see my last blog for more information).
But sometimes you might need to construct a query at runtime. By this I mean not just changing the parameter values, but actually changing the query structure. A good example of this would be a filter, where, depending on what the user wants, you dynamically create a query that culls a set down to what the user is looking for. If you've only got a couple of filter options, you can probably get away with writing multiple compiled queries to cover the permutations, but it only takes a few filter options before you've got a lot of permutations and it becomes unmanageable.
A good example of this is file searching. You can filter a list of files by name, type, size, date modified, etc. The user may only want to filter by one of these filters, for example with "Awesome" as the filename. But the user may also want to filter by multiple filters, for example, "Awesome" as the filename, but modified after 2009/07/07 and more than 20MB in size. To create a static query for each permutation would result in 16 queries (4 squared)!
My first foray into creating dynamic queries is a bit less ambitious than the above example, however. I have a scenario where I need to pull out a number of Tag objects from the database by their IDs. However, the number of the Tag objects needed is determined by the user. They may select 3 Tags, or they may select 6 Tags, or they may select 4 tags; it's up to them.
The most boring approach is, of course, to get each Tag out of the database individually with its own query (the "get each Tag individually" approach):
IList<Tag> list = new List<Tag>();
foreach (int tagId in WantedTagIds)
{
int localTagId = tagId;
Tag theTag = (from tag in context.Tag
where
tag.Account.ID == AccountId &&
tag.ID == localTagId
select tag).First();
list.Add(theTag);
}
You could compile that query to make it run faster, but it's still a slow operation. If the user wants to get 6 Tags, you need to query the database 6 times. Not very cool.
This is where dynamic queries can step in. If the user asks for 3 Tags, you can generate a where clause that gets all three Tags in one go; essentially: tag.ID == 10 || tag.ID == 12 || tag.ID == 14. That way you get all three Tags in one query to the database. So, I wrote some generic type-safe code to perform exactly that: generating a where clause expression from a list of IDs so that a Tag with any of those IDs is retrieved.
To understand how I did this, you need to understand how the where clause in an LINQ expression works. It is easiest to understand if you look at the method-chain form of LINQ rather than the special C# syntax. It looks like this:
IQueryable<Tag> tags = context.Tag.AsQueryable()
.Where(tag => tag.ID == 10);
The Where method takes a parameter that looks like this: Expression<Func<Tag, bool>>. Notice how the Func delegate is wrapped in an Expression? This means that instead of creating an actual anonymous method for the Func delegate, the compiler will instead convert your lambda expression into an Expression Tree.
An Expression Tree is a representation of your expression in an object tree. Here is an object tree that shows the main objects in the expression tree generated by the compiler for the lambda expression in the above example's Where method:
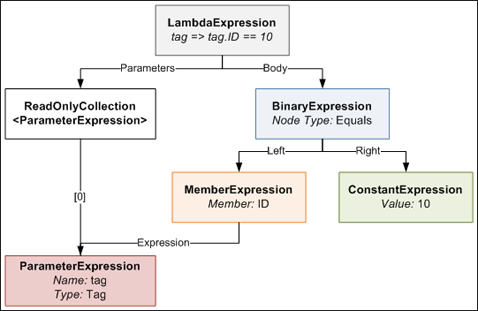
The LambdaExpression has a collection of ParameterExpressions, which are the parameters on the left side of the => symbol in the code. The actual Body of the lambda is made up of a BinaryExpression of type Equals, whose Right side is a ConstantExpression that contains the value of 10, and whose Left side is a MemberExpression. A MemberExpression represents the access of the ID property on the tag parameter.
So if we wanted to represent a more complex expression such as:
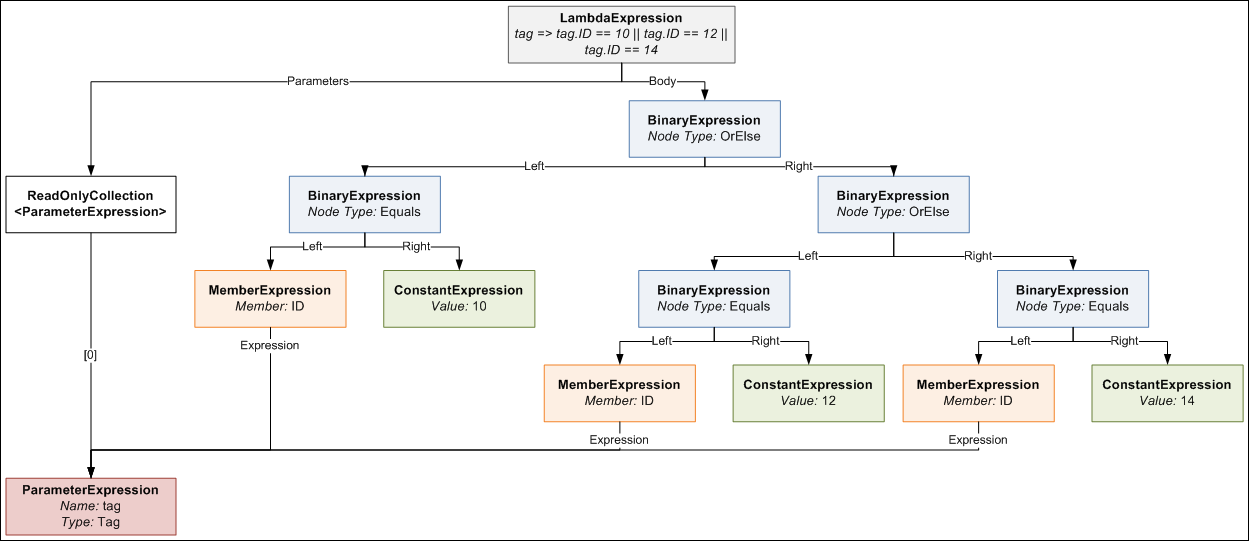
tag => tag.ID == 10 || tag.ID == 12 || tag.ID == 14
this is what the expression tree would look like. It looks a bit daunting, but computers are very good at trees, so writing code to generate such a tree is not too difficult with the help of a little recursion.
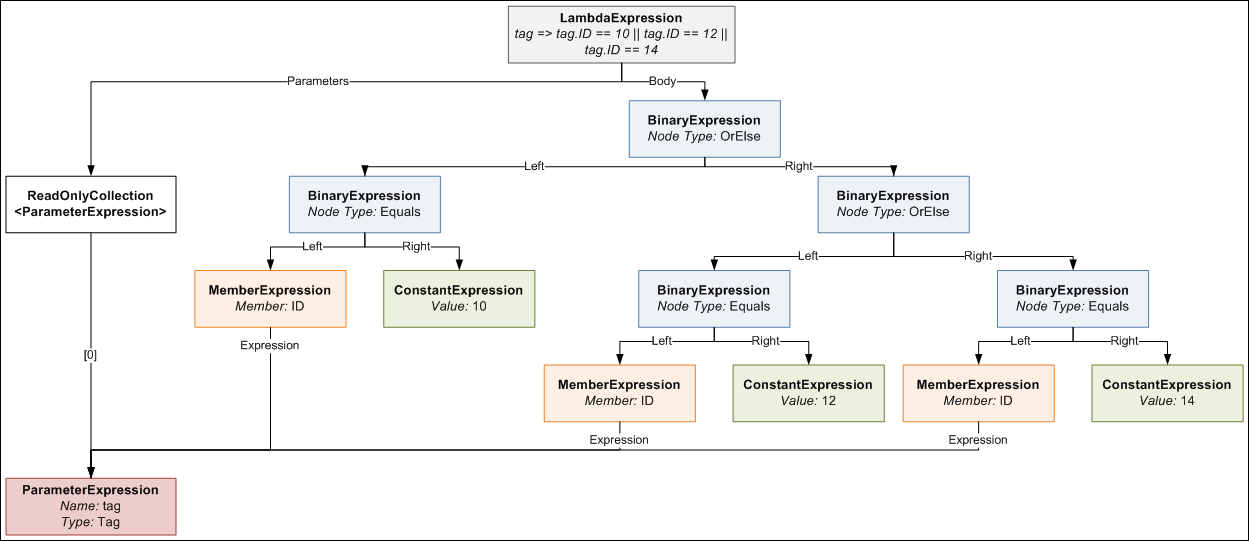{kind=link}
I defined a special utility method that allows you to create an expression tree like the one above that results in a Where expression that accepts a particular tag so long as its ID is in a certain set of IDs. The method is generic and reusable across anywhere where you need a Where filter that gets "this value, or this value, or this value... etc". The public method looks like this:
public static Expression<Func<TValue, bool>> BuildOrExpressionTree<TValue, TCompareAgainst>(
IEnumerable<TCompareAgainst> wantedItems,
Expression<Func<TValue, TCompareAgainst>> convertBetweenTypes)
{
ParameterExpression inputParam = convertBetweenTypes.Parameters[0];
Expression binaryExpressionTree = BuildBinaryOrTree(wantedItems.GetEnumerator(), convertBetweenTypes.Body, null);
return Expression.Lambda<Func<TValue, bool>>(binaryExpressionTree, new[] { inputParam });
}
It's stuffed full of generics which makes it look more complicated than it really is. Here's how you call it:
List<int> ids = new List<int> { 10, 12, 14 };
Expression<Func<Tag, bool>> whereClause = BuildOrExpressionTree<Tag, int>(wantedTagIds, tag => tag.ID);
As I explain how it works, I suggest you keep an eye on the last expression tree diagram. The method defines two generic types, one called TValue which represents the value you are comparing, in this case the Tag class. The other generic type is called TCompareAgainst and is the type of the value you are comparing against, in this case int (because the Tag.ID property is an int).
You pass the method an IEnumerable<TCompareAgainst>, which in our case is an IEnumerable<int>, because we have a list of IDs we are comparing against.
The second parameter ("convertBetweenTypes") can be a bit confusing; let me explain. The expression we are defining for the Where clause takes a Tag and returns a bool (hence the Func<Tag, bool> typed expression). Since the set of values we are comparing against are ints, we can't just do an == between the Tag and an int. To be able to do this comparison, we need to somehow "convert" the Tag we receive into an int for comparison. This is where the second parameter comes in. It defines an Expression that takes a Tag and returns an int (or in generic terms takes a TValue and returns a TCompareAgainst). When you write tag => tag.ID, the compiler generates an Expression Tree that contains a MemberExpression that accesses ID on the tag ParameterExpression. This means wherever we need to do a Tag == int, we instead do a Tag.ID == int by substituting the Tag.ID MemberExpression generated in the place of the Tag. Here's a diagram that explains what I'm ranting about.
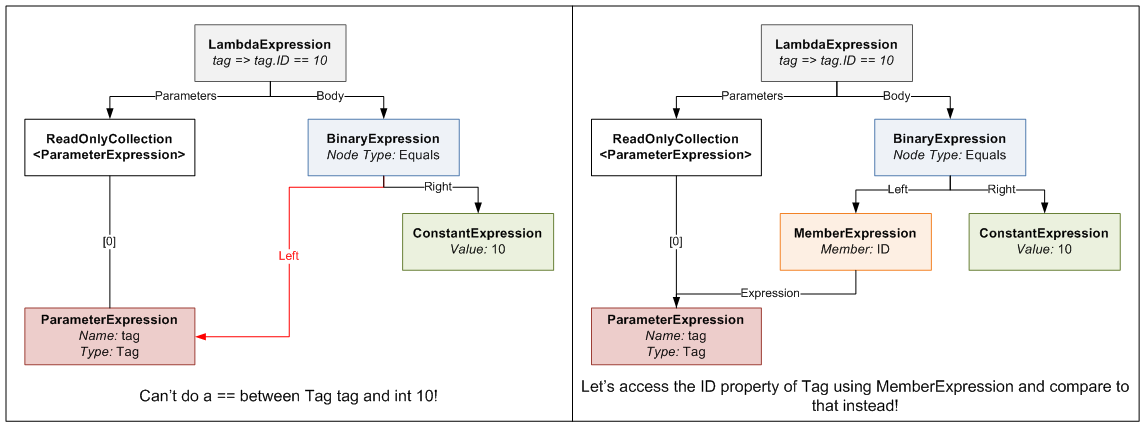{kind=link}
The main purpose of this method is to create the final LambdaExpression that the method returns. It does this by attaching the expression tree built by the BuildBinaryOrTree method (we'll get into this in a second) and the ParameterExpression from the convertBetweenTypes to the final LambdaExpression object.
The BuildBinaryOrTree method looks like this:
private static Expression BuildBinaryOrTree<T>(
IEnumerator<T> itemEnumerator,
Expression expressionToCompareTo,
Expression expression)
{
if (itemEnumerator.MoveNext() == false)
return expression;
ConstantExpression constant = Expression.Constant(itemEnumerator.Current, typeof(T));
BinaryExpression comparison = Expression.Equal(expressionToCompareTo, constant);
BinaryExpression newExpression;
if (expression == null)
newExpression = comparison;
else
newExpression = Expression.OrElse(expression, comparison);
return BuildBinaryOrTree(itemEnumerator, expressionToCompareTo, newExpression);
}
It takes an IEnumerator that enumerates over the wantedItems list (from the BuildOrExpressionTree method), an expression to compare each of these wanted items to (which is the compiler-generated MemberExpression from BuildOrExpressionTreeMethod), and an expression from a previous recursion (starts off as null).
The method creates an Equals BinaryExpression that compares the expressionToCompareTo and the current itemEnumerator value. It then joins this in an OrElse BinaryExpression comparison with the expression from previous recursions. It then takes this new expression and passes it down to the next recursive call. This process continues until itemEnumerator is exhausted at which point the final expression tree is returned.
Once this returned expression tree is placed in its LambdaExpression by the BuildOrExpressionTree method, you end up with a pretty expression tree like this one shown previously. We can then use this expression tree in the where clause of a LINQ method chain query.
Here's the final "generated where clause" query in action:
using (DHEntities context = new DHEntities())
{
int[] wantedTagIds = new[] {12, 24, 1, 4, 32, 19};
Expression<Func<Tag, bool>> whereClause = ExpressionTreeUtil.BuildOrExpressionTree<Tag, int>(wantedTagIds, tag => tag.ID);
IQueryable<Tag> tags = context.Tag.Where(whereClause);
IList<Tag> list = tags.ToList();
}
So how much better is this approach, which is decidedly more complex than the simple "get each Tag at a time" approach? Is it worth the effort? I performed some benchmarks similar to the ones I did in the last blog to find out.
In one benchmark run, I ran these queries, each a hundred times, each getting out the same 6 tags:
- The "get each Tag individually" query (uncompiled)
- The "get each Tag individually" query (compiled)
- The "generated where clause" query. The where clause was regenerated each time.
I then ran the benchmark 100 times so that I could get more reliable averaged values. These are the results I got:
| Average | Standard Deviation | |
|---|---|---|
| "Get Each Tag Individually" Query Loop (Uncompiled) | 3212.2ms | 40.2ms |
| "Get Each Tag Individually" Query Loop (Compiled) | 1349.3ms | 24.2ms |
| "Generated Where Clause" Query Loop | 197.8ms | 5.3ms |
As you can see, the Generated Where Clause approach is quite a lot faster than the individual queries. We can see compiling the Individual query helps, but not enough to beat the Generated Where Clause query, which is faster even though it is recompiled each time! (You can't precompile a dynamic query, obviously). The Generated Where Clause query is 6.8 times faster than the compiled Individual query and a whopping 16.2 times faster than the uncompiled Individual query.
Even though dynamic queries are lots harder than normal static queries, because you have to manually mess with Expression Trees, there are large payoffs to be had in doing so. When used in the appropriate place, dynamic queries are faster than static queries. They could also potentially make your code cleaner, especially in the case of the filter example I talked about at the beginning of this blog. So consider getting up to speed with Expression Trees. It's worth the effort.
Variable Capture in C# with Anonymous Delegates
April 06, 2009 2:00 PM by Daniel Chambers
Anonymous delegates (or, if you're using C# 3.0, lambda expressions) seem fairly simple at first sight. It's just a class-less method that you can pass around and call at will. However, there are some intricacies that aren’t apparent unless you look deeper. In particular, what happens if you use a variable from outside the anonymous delegate inside the delegate? What happens when that variable goes out of scope (say it’s a local variable and the method that contained it returned)?
I’ll run through some small examples that will explain something called “variable capture” and how it relates to anonymous delegates (and therefore, lambda expressions).
The code below for loops and adds a new lambda that returns the index variable from the for loop. After the loop has concluded, all the lambdas created are run and their results written to the console. FYI, Func<TResult> is a .NET built-in delegate that takes no parameters and returns TResult.
List<Func<int>> funcs = new List<Func<int>>();
for (int j = 0; j < 10; j++)
funcs.Add(() => j);
foreach (Func<int> func in funcs)
Console.WriteLine(func());
What will be outputted on the console when this code is run? The answer is ten 10s. Why is this? Because of variable capture. Each lambda has “captured” the variable j, and in essence, extended its scope to outside the for loop. Normally j would be thrown away at the end of the for loop. But because it has been captured, the delegates hold a reference to it. So its final value, after the loop has completed, is 10 and that’s why 10 has been outputted 10 times. (Also, j won’t be garbage collected until the lambda is, since it holds a reference to j.)
In this next example, I’ve added one line of seemingly redundant code, which assigns the j index variable to a temporary variable inside the loop body. The lambda then uses tempJ instead of j. This makes a massive difference to the final output!
List<Func<int>> funcs = new List<Func<int>>();
for (int j = 0; j < 10; j++)
{
int tempJ = j;
funcs.Add(() => tempJ);
}
foreach (Func<int> func in funcs)
Console.WriteLine(func());
This piece of code outputs 0-9 on the console. So why is this so different to the last example? Whereas j’s scope is over the whole for loop (it is the same variable across all loop iterations), tempJ is a new tempJ for every time the loop is run. This means that when the lambdas capture tempJ, they each capture a different tempJ that contains what j was for that particular iteration of the loop.
In this final example, the lambda is created and evaluated within the for loop (and no longer uses tempJ).
for (int j = 0; j < 10; j++)
{
Func<int> func1 = () => j;
Console.WriteLine(func1());
}
This code is similar to the first example; the lambdas capture j whose scope is over the whole for loop. However, unlike the first example, this outputs 0-9 on the console. Why? Because the lambda is executed inside each iteration. So at the point at which each lambda is executed j is 0-9, unlike the first example where the lambdas weren’t executed until j was 10.
In conclusion, using these small examples I’ve shown the implications of variable capture. Variable capture happens when an anonymous delegate uses a variable from the scope outside of itself. This causes the delegate to “capture” the variable (ie hold a reference to it) and therefore the variable will not be garbage collected until the capturer delegate itself is garbage collected.