
F# - Why You Should Give an F (DDD Melbourne Presentation)
July 19, 2014 1:07 PM by Daniel Chambers

Today at DDD Melbourne I gave an introductory presentation on F#, .NET’s general purpose functional programming language.
The abstract for the talk is:
Are you a C# programmer that loves the power and fluency of libraries like LINQ and RX? Do you sometimes find it difficult to write your own expressive, clean, reliable and concurrent code? Have you looked at functional programming and been terrified by math symbols and scary sounding words like "monad" and "category theory"?
In this talk we'll introduce and discuss how to use F# and functional programming techniques to write that cleaner, more expressive and reliable code that you've always wanted; and we promise not to descend into crazy math symbols!
I’ve uploaded the source code and slides to a GitHub repository, so you can examine the awesome in your own time and get excited… in private. :)
I’ve also fixed the copy and paste bug that Mahesh pointed out on Twitter. Can’t let a little typo stand! :)
To compile the SQLClient type provider code, you’ll need to install the AdventureWorksLT sample database to your own SQL Server instance. You can download it from Codeplex under the name “AdventureWorksLT2012_Data”. You can follow this guide on how to attach the downloaded MDF file to SQL Server (why Microsoft don’t provide a .BAK file to restore instead, I don’t know!)
To get started coding in F#, I recommend the following tools:
- Visual Studio 2013 – Make sure you update the included “Visual F#” extension to the latest version
- Visual F# Power Tools Extension
- F# Outlining Extension
To learn more about F#, I highly recommend:
- F# For Fun and Profit – F# and functional programming explained in simple understandable language – no crazy maths stuff
- Try F# – Online syntax tutorials and in-browser compiler
- The F# Software Foundation – The F# community hub; has links to videos, guides and commonly used libraries
F# people to follow on Twitter (obviously not exhaustive!):
- Don Syme – The Benevolent Dictator for Life of the F# language (he is its designer)
- Tomas Petricek – Super F# enthusiast and founding member of the F# Foundation
- Scott Wlaschin – Scott is the author of F# For Fun and Profit
FSharp.Azure 1.0 - with support for option types
May 24, 2014 9:47 AM by Daniel Chambers (last modified on May 24, 2014 9:58 AM)
This week I published the 1.0 stable release of FSharp.Azure on NuGet. Compared to the beta, it has one extra feature I slipped in: support for using option types on your record fields.
For those unfamiliar with F#, the option type is an F# construct that allows you to express the presence or absence of a value. It is similar to Nullable<T>, however it works for all types, instead of just value types. C# developers are used to using null as the “absence” value for reference types, as all references are nullable by default in the CLR. However, when writing F# any type you define is not allowed to be nullable by default, regardless of the fact that it may be a CLR reference type under the covers. This is where the F# option type comes in; when you want to allow the absence of something, you must be explicit and describe that fact using the option type. This is great because it means that you are much less likely to be passed null (ie. the “absence”) when you don’t expect it and get an error such as the irritating NullReferenceException. You can basically view the option type as opt-in nullability.
Here’s an example record type for use with FSharp.Azure that uses option types:
type Game =
{ [<PartitionKey>] Developer : string
[<RowKey>] Name : string
ReleaseYear : int option
Notes : string option }
You could insert one of these records into table storage like this:
let game =
{ Developer = "343 Industries"
Name = "Halo 5"
ReleaseYear = None
Notes = None }
let result = game |> Insert |> inGameTable
The inGameTable function is a FSharp.Azure helper function and you can see how it was defined in this previous post.
Note the use of the None value for ReleaseYear and Notes. We’re explicitly saying we’re omitting a value for those two fields. When translated to Azure table storage this means for the row that will be inserted for this record those two properties will not be defined. Remember that in table storage, unlike relational databases, not all rows in a table need have the same properties.
If we later want to update that record in table storage and provide values for ReleaseYear and Notes, we can:
let modifiedGame =
{ game with
ReleaseYear = Some 2015
Notes = Some "Has yet to be released." }
let result = modifiedGame |> ForceReplace |> inGameTable
Another nice ability that using option types with FSharp.Azure provides us is being able to use Merge to update the row in table storage with only the properties that are either not option types or are option typed and have Some value (ie are not None). For example:
let modifiedGame =
{ game with
ReleaseYear = None
Notes = Some "Will be bigger than Halo 4!" }
let result = modifiedGame |> ForceMerge |> inGameTable
Because we’re using a Merge operation, the above will change the Notes property in table storage, but will not change the existing ReleaseYear value.
To play with FSharp.Azure, use NuGet to install the package “FSharp.Azure”. The source code is available on GitHub.
Querying Azure Table Storage Data using FSharp.Azure
May 11, 2014 12:06 PM by Daniel Chambers (last modified on May 18, 2014 2:40 PM)
In my last post, I showed how to use FSharp.Azure to modify data in Azure table storage. FSharp.Azure is a library I recently released that allows F# developers to write idiomatic F# code to talk to Azure table storage. In this post, we’ll look at the opposite of data modification: data querying.
Getting Started
To use FSharp.Azure, install the NuGet package: FSharp.Azure. At the time of writing the package is marked as beta, so you will need to include pre-releases by using the checkbox on the UI, or using the (v1.0.0 has been released!)–Pre flag on the console.
Once you’ve installed the package, you need to open the TableStorage module to use the table storage functions:
open DigitallyCreated.FSharp.Azure.TableStorage
Compatible Types
To provide an idiomatic F# experience when querying table storage, FSharp.Azure supports the use of record types when querying. For example, the following record type would be used to read a table with columns that match the field names:
type Game =
{ Name : string
Developer : string
HasMultiplayer : bool
Notes : string }
We will use this record type in the examples below. We will also assume, for the sake of these examples, that the Developer field is also used as the PartitionKey and the Name field is used as the RowKey.
FSharp.Azure also supports querying class types that implement the Microsoft.WindowsAzure.Storage.Table.ITableEntity interface.
Setting up
The easiest way to use the FSharp.Azure API is to define a quick helper function that allows you to query for rows from a particular table:
open Microsoft.WindowsAzure.Storage open Microsoft.WindowsAzure.Storage.Table let account = CloudStorageAccount.Parse "UseDevelopmentStorage=true;" //Or your connection string here let tableClient = account.CreateCloudTableClient() let fromGameTable q = fromTable tableClient "Games" q
The fromGameTable function fixes the tableClient and table name parameters of the fromTable function, so you don't have to keep passing them. This technique is very common when using the FSharp.Azure API.
Getting everything
Here's how we'd query for all rows in the "Games" table:
let games = Query.all<Game> |> fromGameTable
games above is of type seq<Game * EntityMetadata>. The EntityMetadata type contains the Etag and Timestamp of each Game. Here's how you might work with that:
let gameRecords = games |> Seq.map fst let etags = games |> Seq.map (fun game, metadata -> metadata.Etag)
The etags in particular are useful when updating those records in table storage, because they allow you to utilise Azure Table Storage's optimistic concurrency protection to ensure nothing else has changed the record since you queried for it.
Filtering with where
The Query.where function allows you to use an F# quotation of a lambda to specify what conditions you want to filter by. The lambda you specify must be of type:
'T -> SystemProperties -> bool
The SystemProperties type allows you to construct filters against system properties such as the Partition Key and Row Key, which are the only two properties that are indexed by Table Storage, and therefore the ones over which you will most likely be performing filtering.
For example, this is how we'd get an individual record by PartitionKey and RowKey:
let halo4, metadata =
Query.all<Game>
|> Query.where <@ fun g s -> s.PartitionKey = "343 Industries" && s.RowKey = "Halo 4" @>
|> fromGameTable
|> Seq.head
You can, however, query over properties on your record type too. Be aware that queries over those properties are not indexed by Table Storage and as such will suffer performance penalties.
For example, if we wanted to find all multiplayer games made by Valve, we could write:
let multiplayerValveGames =
Query.all<Game>
|> Query.where <@ fun g s -> s.PartitionKey = "Valve" && g.HasMultiplayer @>
|> fromGameTable
The following operators/functions are supported for use inside the where lambda:
- The
=,<>,<,<=,>,>=operators - The
notfunction
Taking only the first n rows
Table storage allows you to limit the query results to be only the first 'n' results it finds. Naturally, FSharp.Azure supports this.
Here's an example query that limits the results to the first 5 multiplayer games made by Valve:
let multiplayerValveGames =
Query.all<Game>
|> Query.where <@ fun g s -> s.PartitionKey = "Valve" && g.HasMultiplayer @>
|> Query.take 5
|> fromGameTable
Query segmentation
Azure table storage may not return all the results that match the query in one go. Instead it may split the results over multiple segments, each of which must be queried for separately and sequentially. According to MSDN, table storage will start segmenting results if:
- The resultset contains more than 1000 items
- The query took longer than five seconds
- The query crossed a partition boundary
FSharp.Azure supports handling query segmentation manually as well as automatically. The fromTable function we used in the previous examples returns a seq that will automatically query for additional segments as you iterate.
If you want to handle segmentation manually, you can use the fromTableSegmented function instead of fromTable. First, define a helper function:
let fromGameTableSegmented c q = fromTableSegmented tableClient "Games" c q
The fromGameTableSegmented function will have the type:
TableContinuationToken option -> EntityQuery<'T> -> List<'T * EntityMetadata> * TableContinuationToken option
This means it takes an optional continuation token and the query, and returns the list of results in that segment, and optionally the continuation token used to access the next segment, if any.
Here's an example that gets the first two segments of query results:
let query = Query.all<Game>
let games1, segmentToken1 =
query |> fromGameTableSegmented None //None means querying for the first segment (ie. no continuation)
//We're making the assumption segmentToken1 here is not None and therefore
//there is another segment to read. In practice, this is a very poor assumption
//to make, since segmentation is performed arbitrarily by table storage
if segmentToken1.IsNone then failwith "No segment 2!"
let games2, segmentToken2 =
query |> fromGameTableSegmented segmentToken1
In practice, you'd probably write a recursive function or a loop to iterate through the segments until a certain condition.
Asynchronous support
FSharp.Azure also supports asynchronous equivalents of fromTable and fromTableSegmented. To use them, you would first create your helper functions:
let fromGameTableAsync q = fromTableAsync tableClient "Games" q let fromGameTableSegmentedAsync c q = fromTableSegmentedAsync tableClient "Games" c q
fromTableAsync automatically and asynchronously makes requests for all the segments and returns all the results in a single seq. Note that unlike fromTable, all segments are queried for during the asynchronous operation, not during sequence iteration. (This is because seq doesn't support asynchronous iteration.)
Here's an example of using fromTableAsync:
let valveGames =
Query.all<Game>
|> Query.where <@ fun g s -> s.PartitionKey = "Valve" @>
|> fromGameTableAsync
|> Async.RunSynchronously
And finally, an example using the asynchronous segmentation variant:
let asyncOp = async {
let query = Query.all<Game>
let! games1, segmentToken1 =
query |> fromGameTableSegmentedAsync None //None means querying for the first segment (ie. no continuation)
//We're making the assumption segmentToken1 here is not None and therefore
//there is another segment to read. In practice, this is a very poor assumption
//to make, since segmentation is performed arbitrarily by table storage
if segmentToken1.IsNone then failwith "No segment 2!"
let! games2, segmentToken2 =
query |> fromGameTableSegmentedAsync segmentToken1
return games1 @ games2
}
let games = asyncOp |> Async.RunSynchronously
Conclusion
In this post, we’ve covered the nitty gritty details of querying with FSharp.Azure. Hopefully you find this series of posts and the library itself useful; if you have, please do leave a comment or tweet to me at @danielchmbrs.
Modifying Azure Table Storage Data using FSharp.Azure
May 08, 2014 1:23 PM by Daniel Chambers (last modified on May 24, 2014 9:53 AM)
In my previous post I gave a quick taster of how to modify data in Azure table storage using FSharp.Azure, but I didn’t go into detail. FSharp.Azure is the new F# library that I’ve recently released that lets you talk to Azure table storage using an idiomatic F# API surface. In this post, we’re going to go into deep detail about all the features FSharp.Azure provides for modifying data in table storage.
Getting Started
To use FSharp.Azure, install the NuGet package: FSharp.Azure. At the time of writing the package is marked as beta, so you will need to include pre-releases by using the checkbox on the UI, or using the (v1.0.0 has been released!)–Pre flag on the console.
Once you’ve installed the package, you need to open the TableStorage module to use the table storage functions:
open DigitallyCreated.FSharp.Azure.TableStorage
Compatible Types
In order to provide an idiomatic F# experience when talking to Azure table storage, FSharp.Azure supports the use of record types. For example, this is a record you could store in table storage:
type Game =
{ Name : string
Developer : string
HasMultiplayer : bool
Notes : string }
Note that the record fields must be of types that Azure table storage supports; that is:
stringintint64booldoubleGuidDateTimeOffsetbyte[]
In addition to record types, you can also use classes that implement the standard Microsoft.WindowsAzure.Storage.Table.ITableEntity interface.
For the remainder of this post however, we will focus on using record types.
Specifying the Partition Key and Row Key
One of the design goals of the FSharp.Azure API is to ensure that your record types are persistence independent. This is unlike the standard ITableEntity interface, which forces you to implement the PartitionKey and RowKey properties. (And therefore if you're using that interface, you don't need to do any of things in this section.)
However, FSharp.Azure still needs to be able to derive a Partition Key and Row Key from your record type in order to be able to insert it (etc) into table storage. There are three ways of setting this up:
Attributes
You can use attributes to specify which of your record fields are the PartitionKey and RowKey fields. Here's an example:
type Game =
{ [<RowKey>] Name : string
[<PartitionKey>] Developer : string
HasMultiplayer : bool
Notes : string }
The IEntityIdentifiable interface
Sometimes you need to be able to have more control over the values of the Partition Key and Row Key. For example, if we add a Platform field to the Game record type, we will need to change the RowKey, or else we would be unable to store two Games with the same Name and Developer, but different Platforms.
To cope with this situation, you can implement an interface on the record type:
type Game =
{ Name: string
Developer : string
Platform: string
HasMultiplayer : bool
Notes : string }
interface IEntityIdentifiable with
member g.GetIdentifier() =
{ PartitionKey = g.Developer; RowKey = sprintf "%s-%s" g.Name g.Platform }
In the above example, we've derived the Row Key from both the Name and Platform fields.
Replace EntityIdentiferReader.GetIdentifier with your own function
For those purists who don't want to dirty their types with interfaces and attributes, there is the option of replacing a statically stored function with a different implementation. For example:
let getGameIdentifier g =
{ PartitionKey = g.Developer; RowKey = sprintf "%s-%s" g.Name g.Platform }
EntityIdentiferReader.GetIdentifier <- getGameIdentifier
The type of GetIdentifier is:
'T -> EntityIdentifier
Setting up
The first thing to do is define a helper function inGameTable that will allow us to persist records to table storage into an existing table called "Games".
open Microsoft.WindowsAzure.Storage open Microsoft.WindowsAzure.Storage.Table let account = CloudStorageAccount.Parse "UseDevelopmentStorage=true;" //Or your connection string here let tableClient = account.CreateCloudTableClient() let inGameTable game = inTable tableClient "Games" game
This technique of taking a library function and fixing the tableClient and table name parameters is very common when using FSharp.Azure's API, and you can do it to other similar library functions.
Operations
FSharp.Azure supports all the different Azure table storage modification operations and describes them in the Operation discriminated union:
type Operation<'T> =
| Insert of entity : 'T
| InsertOrMerge of entity : 'T
| InsertOrReplace of entity : 'T
| Replace of entity : 'T * etag : string
| ForceReplace of entity : 'T
| Merge of entity : 'T * etag : string
| ForceMerge of entity : 'T
| Delete of entity : 'T * etag : string
| ForceDelete of entity : 'T
The Operation discriminated union is used to wrap your record instance and describes the modification operation, but doesn't actually perform it. You act upon the Operation by passing it to our inGameTable helper function (which calls the inTable library function). See below for examples for all the different types of operations.
Inserting
In order to insert a row into table storage we wrap our record using Insert and pass it to our helper function, like so:
let game =
{ Name = "Halo 4"
Platform = "Xbox 360"
Developer = "343 Industries"
HasMultiplayer = true
Notes = "Finished the game in Legendary difficulty." }
let result = game |> Insert |> inGameTable
result is of type OperationResult:
type OperationResult =
{ HttpStatusCode : int
Etag : string }
The other variations of Insert (InsertOrMerge and InsertOrReplace) can be used in a similar fashion:
let result = game |> InsertOrMerge |> inGameTable let result = game |> InsertOrReplace |> inGameTable
Replacing
Replacing a record in table storage can be done similarly to inserting, with one caveat. Azure table storage provides optimistic concurrency protection using etags, so when replacing an existing record you also need to pass the etag that matches the row in table storage. For example:
let game =
{ Name = "Halo 4"
Platform = "Xbox 360"
Developer = "343 Industries"
HasMultiplayer = true
Notes = "Finished the game in Legendary difficulty." }
let originalResult = game |> Insert |> inGameTable
let gameChanged =
{ game with
Notes = "Finished the game in Legendary and Heroic difficulty." }
let result = (gameChanged, originalResult.Etag) |> Replace |> inGameTable
If you want to bypass the optimistic concurrency protection and just replace the row anyway, you can use ForceReplace instead of Replace:
let result = gameChanged |> ForceReplace |> inGameTable
Merging
Merging is handled similarly to replacing, in that it requires the use of an etag. Merging can be used when you want to modify a subset of properties on a row in table storage, or a different set of properties on the same row, without affecting the other existing properties on the row.
As a demonstration, we'll define a new GameSummary record that omits the Notes field, so we can update the row without touching the Notes property at all.
type GameSummary =
{ Name : string
Developer : string
Platform : string
HasMultiplayer : bool }
interface IEntityIdentifiable with
member g.GetIdentifier() =
{ PartitionKey = g.Developer; RowKey = sprintf "%s-%s" g.Name g.Platform }
Now we'll use Merge to update an inserted row:
let game =
{ Name = "Halo 4"
Platform = "Xbox 360"
Developer = "343 Industries"
HasMultiplayer = true
Notes = "Finished the game in Legendary difficulty." }
let originalResult = game |> Insert |> inGameTable
let gameSummary =
{ GameSummary.Name = game.Name
Platform = game.Platform
Developer = game.Developer
HasMultiplayer = false } //Change HasMultiplayer
let result = (gameSummary, originalResult.Etag) |> Merge |> inGameTable
Like Replace, Merge has a ForceMerge variant that ignores the optimistic concurrency protection:
let result = gameSummary |> ForceMerge |> inGameTable
Deleting
Deleting is handled similarly to Replace and Merge and requires an etag.
let game =
{ Name = "Halo 4"
Platform = "Xbox 360"
Developer = "343 Industries"
HasMultiplayer = true
Notes = "Finished the game in Legendary difficulty." }
let originalResult = game |> Insert |> inGameTable
let result = (game, originalResult.Etag) |> Delete |> inGameTable
A ForceDelete variant exists for deleting even if the row has changed:
let result = game |> ForceDelete |> inGameTable
Often you want to be delete a row without actually loading it first. You can do this easily by using the EntityIdentifier record type which just lets you specify the Partition Key and Row Key of the row you want to delete:
let result =
{ EntityIdentifier.PartitionKey = "343 Industries"; RowKey = "Halo 4-Xbox 360" }
|> ForceDelete
|> inGameTable
Asynchronous Support
The inGameTable helper function we've been using uses the inTable library function, which means that operations are processed synchronously when inTable is called. Sometimes you want to be able to process operations asynchronously.
To do this we'll define a new helper function that will use inTableAsync instead:
let inGameTableAsync game = inTableAsync tableClient "Games" game
Then we can use that in a similar fashion:
let game =
{ Name = "Halo 4"
Platform = "Xbox 360"
Developer = "343 Industries"
HasMultiplayer = true
Notes = "Finished the game in Legendary difficulty." }
let result = game |> Insert |> inGameTableAsync |> Async.RunSynchronously
One obvious advantage of asynchrony is that we can very easily start performing operations in parallel. Here's an example where we insert two records in parallel:
let games =
[
{ Name = "Halo 4"
Platform = "Xbox 360"
Developer = "343 Industries"
HasMultiplayer = true
Notes = "Finished the game in Legendary difficulty." }
{ Name = "Halo 5"
Platform = "Xbox One"
Developer = "343 Industries"
HasMultiplayer = true
Notes = "Haven't played yet." }
]
let results =
games
|> Seq.map (Insert >> inGameTableAsync)
|> Async.Parallel
|> Async.RunSynchronously
Batching
Azure table storage provides the ability to take multiple operations and submit them to be processed all together in one go. There are many reasons why you might want to batch up operations, such as
- Reducing cost - since you are billed on a per transaction basis, batching reduces your number of transactions
- Performance - instead of performing multiple HTTP requests you can batch them together into one (or more) batch requests
However, there are some restrictions on what can go into a batch. They are:
- All the operations in a single batch must deal with rows in the same partition in the same table
- You cannot perform multiple operations on a single row in the same batch
- There can be no more than 100 operations in a single batch
FSharp.Azure provides functions to make batching easy. First we'll define a batching helper function:
let inGameTableAsBatch game = inTableAsBatch tableClient "Games" game
Now let's generate 150 Halo games and 50 Portal games, batch them up and insert them into table storage:
let games =
[seq { for i in 1 .. 50 ->
{ Developer = "Valve"; Name = sprintf "Portal %i" i; Platform = "PC"; HasMultiplayer = true; Notes = "" } };
seq { for i in 1 .. 150 ->
{ Developer = "343 Industries"; Name = sprintf "Halo %i" i; Platform = "Xbox One"; HasMultiplayer = true; Notes = "" } }]
|> Seq.concat
|> Seq.toList
let results =
games
|> Seq.map Insert
|> autobatch
|> List.map inGameTableAsBatch
The autobatch function splits the games by Partition Key and then into groups of 100. This means we will have created three batches, one with 50 Portals, one with 100 Halos, and another with the final 50 Halo games. Each batch is then sequentially submitted to table storage.
If we wanted to do this asynchronously and in parallel, we could first define another helper function:
let inGameTableAsBatchAsync game = inTableAsBatchAsync tableClient "Games" game
Then use it:
let results =
games
|> Seq.map Insert
|> autobatch
|> List.map inGameTableAsBatchAsync
|> Async.Parallel
|> Async.RunSynchronously
Conclusion
In this post, we’ve gone into gory detail about how to modify data in Azure table storage using FSharp.Azure. In a future post, I’ll do a similar deep dive into the opposite side: how to query data from table storage.
Announcing FSharp.Azure - An Idiomatic F# Azure Storage API
May 06, 2014 12:03 PM by Daniel Chambers (last modified on May 18, 2014 2:41 PM)
Over the last few months I’ve been learning F#, .NET’s functional programming language. One of the first things I started fiddling with was using F# to read and write to Azure table storage. Being a .NET language, F# can of course use the regular Microsoft WindowsAzure.Storage API to work with table storage, however that forces you to write F# in a very non-functional way. For example, the standard storage API forces you to use mutable classes as your table storage entities, and mutability is a functional programming no no.
There’s an existing open-source library called Fog, which provides an F# API to talk to the Azure storage services, but its table storage support is a thin wrapper over an old version of the WindowsAzure.Storage API. Unfortunately this means you still have to deal with mutable objects (boo hiss!). Also, Fog doesn’t support querying table storage.
So with my fledgling F# skills, I decided to see if I could do better; FSharp.Azure was born. In this first version, it only supports table storage, but I hope to in the future expand it to cover the other Azure storage services too.
FSharp.Azure, like Fog, is a wrapper over WindowsAzure.Storage, however it exposes a much more idiomatic F# API surface. This means you can talk to table storage by composing together F# functions, querying using F# quotations, and do it all using immutable F# record types.
But enough blathering, let’s have a quick taste test!
Modifying Data in Table Storage
Imagine we had a record type that we wanted to save into table storage:
open DigitallyCreated.FSharp.Azure.TableStorage
type Game =
{ [<PartitionKey>] Developer: string
[<RowKey>] Name: string
HasMultiplayer: bool }
Note the attributes on the record fields that mark which fields are used as the PartitionKey and RowKey properties for table storage.
We’ll first define a helper function inGameTable that will allow us to persist these Game records to table storage into an existing table called "Games":
open Microsoft.WindowsAzure.Storage open Microsoft.WindowsAzure.Storage.Table let account = CloudStorageAccount.Parse "UseDevelopmentStorage=true;" //Or your connection string here let tableClient = account.CreateCloudTableClient() let inGameTable game = inTable tableClient "Games" game
Now that the set up ceremony is done, let's insert a new Game into table storage:
let game = { Developer = "343 Industries"; Name = "Halo 4"; HasMultiplayer = true }
let result = game |> Insert |> inGameTable
Let's say we want to modify this game and update it in table storage:
let modifiedGame = { game with HasMultiplayer = false }
let result2 = (modifiedGame, result.Etag) |> Replace |> inGameTable
Want more detail about modifying data in table storage? Check out this post.
Querying Data from Table Storage
First we need to set up a little helper function for querying from the "Games" table:
let fromGameTable q = fromTable tableClient "Games" q
Here's how we'd query for an individual record by PartitionKey and RowKey:
let halo4, metadata =
Query.all<Game>
|> Query.where <@ fun g s -> s.PartitionKey = "343 Industries" && s.RowKey = "Halo 4" @>
|> fromGameTable
|> Seq.head
If we wanted to find all multiplayer games made by Valve:
let multiplayerValveGames =
Query.all<Game>
|> Query.where <@ fun g s -> s.PartitionKey = "Valve" && g.HasMultiplayer @>
|> fromGameTable
For more detail about querying, check out this post.
NuGet
To get FSharp.Azure, use NuGet to install “FSharp.Azure”. At the time of writing, it’s still in beta so you’ll need to include pre-releases (tick the box on the GUI, or use the -Pre flag from the console). (v1.0.0 has been released!)
In future blog posts, I’ll go into more detail about modification operations, further querying features, asynchronous support and all the other bits FSharp.Azure supports. In the meantime, please visit GitHub for more information and to see the source code.
The Corporate BS Generator Windows 8 App
October 03, 2012 1:23 PM by Daniel Chambers (last modified on October 03, 2012 1:29 PM)
On my last gig my friend Mahesh sent the team a link to Tommy Butler’s simple Corporate BS Generator page, and naturally we all cracked up. For the whole day any chat over Skype was derailed with someone chucking in some random BS, for example “that’s a good idea, but does it conveniently enable visionary services?” It was a Windows 8 app gig, so we were all neck deep in WinRT and XAML, and it came to me that this would be awesome as an app for Windows 8.
Today, I’d like to announce the release of the Corporate BS Generator Windows 8 app on the Windows Store. Tommy has given me his blessing to bring the lulz to Windows 8 and Windows RT users.
Have you ever sat through a corporate presentation and been dazzled by fancy buzzword-filled phrases? Have you ever wished that you were capable of effortlessly making normal, typical and common-sense things sound slick, hip, modern and cool? The Corporate BS Generator can help you get ahead in an industry where spin, buzzwords and vagueness reign supreme.
Swipe or click your way through randomly generated Corporate BS and impress your executives at your next meeting. Your BS will sound so good that they’ll just nod enthusiastically even though they have no idea what your plan to “compellingly target future-proof synergy” actually means!
Here’s a sampling of some of the BS it generates:
- dynamically e-enable world-class solutions
- globally engage intuitive methodologies
- credibly transition ethical communities
- uniquely embrace progressive e-tailers
- dynamically productise orthogonal scenarios
- continually foster stand-alone supply chains
Cracked up yet? Grab the app from the Windows Store now.

Async/Await - The Edge Cases and Unit Testing Presentation
October 03, 2012 12:29 PM by Daniel Chambers

Tonight I gave a short presentation at Devevening titled “Async/Await – The Edge Cases and Unit Testing”. Here’s the abstract:
In this talk we'll look at the new async await feature in C# 5, but we'll go beyond the typical toy examples and look at edge cases like exception handling, task cancellation and how we can approach unit testing asynchronous methods.
I’ve uploaded the source code and slides to a BitBucket repository, so for those who want to inspect the examples at their own leisure, please clone away:
- Source code (specifically revision 394d1e3cf9f5 was used in this talk)
- Presentation slides
I hope to make an extended version of the talk and present that at a future user group; I’d like to cover things in a little more detail, look at the history of async over the life of the .NET Framework, cover unit testing a bit more thoroughly, and maybe even take a peek under the covers at what the compiler generates when you write an async method. Stay tuned!
More Lessons from the LINQ Database Query Performance Land
July 19, 2011 2:00 PM by Daniel Chambers (last modified on July 19, 2011 2:20 PM)
Writing LINQ against databases using providers like LINQ to SQL and Entity Framework is harder than it first appears. There are many different ways to write the same query in LINQ and many of them cause LINQ providers to generate really horrible SQL. LINQ to SQL is quite the offender in this area but, as we’ll see, Entity Framework can write bad SQL too. The trick is knowing how to write LINQ that doesn’t result in horribly slow queries, so in this blog post we’ll look at an interesting table joining scenario where different LINQ queries produce SQL of vastly different quality.
Here’s the database schema:
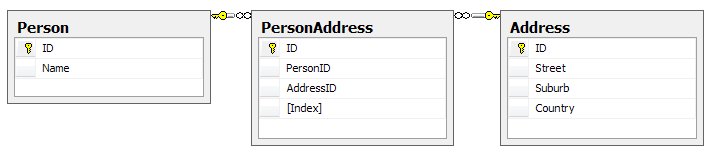
Yes, this may not be the best database design as you could arguably merge PersonAddress and Address, but it’ll do for an example; it’s the query structure we’re more interested in rather than the contents of the tables. One thing to note is that the Index column on PersonAddress is there to number the addresses associated with the person, ie Address 1, Address 2. There cannot be two PersonAddresses for the same person with the same Index. Our entity classes map exactly to these tables.
Let’s say we want to write a query for reporting purposes that flattens this structure out like so:

Optimally, we’d like the LINQ query to write this SQL for us (or at least SQL that performs as well as this; this has a cost of 0.0172):
SELECT p.Name, a1.Street AS 'Street 1', a1.Suburb AS 'Suburb 1', a1.Country AS 'Country 1',
a2.Street AS 'Street 2', a2.Suburb AS 'Suburb 2', a2.Country AS 'Country 2'
FROM Person p
LEFT OUTER JOIN PersonAddress pa1 on p.ID = pa1.PersonID AND pa1.[Index] = 1
LEFT OUTER JOIN PersonAddress pa2 on p.ID = pa2.PersonID AND pa2.[Index] = 2
LEFT OUTER JOIN [Address] a1 on a1.ID = pa1.AddressID
LEFT OUTER JOIN [Address] a2 on a2.ID = pa2.AddressID
One way of doing this using LINQ, and taking advantage of navigation properties on the entity classes, might be this:
from person in context.People
let firstAddress = person.PersonAddresses.FirstOrDefault(pa => pa.Index == 1).Address
let secondAddress = person.PersonAddresses.FirstOrDefault(pa => pa.Index == 2).Address
select new
{
Name = person.Name,
Street1 = firstAddress.Street,
Suburb1 = firstAddress.Suburb,
Country1 = firstAddress.Country,
Street2 = secondAddress.Street,
Suburb2 = secondAddress.Suburb,
Country2 = secondAddress.Country,
}
However, using LINQ to SQL, the following SQL is generated (and its cost is 0.0458, which is nearly three times the cost of the SQL we’re aiming for):
SELECT [t0].[Name], (
SELECT [t3].[Street]
FROM (
SELECT TOP (1) [t1].[AddressID] FROM [PersonAddress] AS [t1]
WHERE ([t1].[Index] = 1) AND ([t1].[PersonID] = [t0].[ID])
) AS [t2]
INNER JOIN [Address] AS [t3] ON [t3].[ID] = [t2].[AddressID]
) AS [Street1], (
SELECT [t6].[Suburb]
FROM (
SELECT TOP (1) [t4].[AddressID] FROM [PersonAddress] AS [t4]
WHERE ([t4].[Index] = 1) AND ([t4].[PersonID] = [t0].[ID])
) AS [t5]
INNER JOIN [Address] AS [t6] ON [t6].[ID] = [t5].[AddressID]
) AS [Suburb1], (
SELECT [t9].[Country]
FROM (
SELECT TOP (1) [t7].[AddressID] FROM [PersonAddress] AS [t7]
WHERE ([t7].[Index] = 1) AND ([t7].[PersonID] = [t0].[ID])
) AS [t8]
INNER JOIN [Address] AS [t9] ON [t9].[ID] = [t8].[AddressID]
) AS [Country1], (
SELECT [t12].[Street]
FROM (
SELECT TOP (1) [t10].[AddressID] FROM [PersonAddress] AS [t10]
WHERE ([t10].[Index] = 2) AND ([t10].[PersonID] = [t0].[ID])
) AS [t11]
INNER JOIN [Address] AS [t12] ON [t12].[ID] = [t11].[AddressID]
) AS [Street2], (
SELECT [t15].[Suburb]
FROM (
SELECT TOP (1) [t13].[AddressID] FROM [PersonAddress] AS [t13]
WHERE ([t13].[Index] = 2) AND ([t13].[PersonID] = [t0].[ID])
) AS [t14]
INNER JOIN [Address] AS [t15] ON [t15].[ID] = [t14].[AddressID]
) AS [Suburb2], (
SELECT [t18].[Country]
FROM (
SELECT TOP (1) [t16].[AddressID] FROM [PersonAddress] AS [t16]
WHERE ([t16].[Index] = 2) AND ([t16].[PersonID] = [t0].[ID])
) AS [t17]
INNER JOIN [Address] AS [t18] ON [t18].[ID] = [t17].[AddressID]
) AS [Country2]
FROM [Person] AS [t0]
Hoo boy, that’s horrible SQL! Notice how it’s doing a whole table join for every column? Imagine how that query would scale the more columns you had in your LINQ query! Epic fail.
Entity Framework (v4) fares much better, writing a ugly duckling query that is actually beautiful inside, performing at around the same speed as the target SQL (0.0172):
SELECT [Extent1].[ID] AS [ID], [Extent1].[Name] AS [Name], [Extent3].[Street] AS [Street],
[Extent3].[Suburb] AS [Suburb], [Extent3].[Country] AS [Country], [Extent5].[Street] AS [Street1],
[Extent5].[Suburb] AS [Suburb1], [Extent5].[Country] AS [Country1]
FROM [dbo].[Person] AS [Extent1]
OUTER APPLY (
SELECT TOP (1) [Extent2].[PersonID] AS [PersonID], [Extent2].[AddressID] AS [AddressID],
[Extent2].[Index] AS [Index]
FROM [dbo].[PersonAddress] AS [Extent2]
WHERE ([Extent1].[ID] = [Extent2].[PersonID]) AND (1 = [Extent2].[Index]) ) AS [Element1]
LEFT OUTER JOIN [dbo].[Address] AS [Extent3] ON [Element1].[AddressID] = [Extent3].[ID]
OUTER APPLY (
SELECT TOP (1) [Extent4].[PersonID] AS [PersonID], [Extent4].[AddressID] AS [AddressID],
[Extent4].[Index] AS [Index]
FROM [dbo].[PersonAddress] AS [Extent4]
WHERE ([Extent1].[ID] = [Extent4].[PersonID]) AND (2 = [Extent4].[Index]) ) AS [Element2]
LEFT OUTER JOIN [dbo].[Address] AS [Extent5] ON [Element2].[AddressID] = [Extent5].[ID]
So, if we’re stuck using LINQ to SQL and can’t jump ship to the more mature Entity Framework, how can we manipulate the LINQ to force it to write better SQL? Let’s try putting the Index predicate (ie pa => pa.Index == 1) into the join instead:
from person in context.Persons
join pa in context.PersonAddresses on new { person.ID, Index = 1 } equals new { ID = pa.PersonID, pa.Index } into pa1s
join pa in context.PersonAddresses on new { person.ID, Index = 2 } equals new { ID = pa.PersonID, pa.Index } into pa2s
from pa1 in pa1s.DefaultIfEmpty()
from pa2 in pa2s.DefaultIfEmpty()
let firstAddress = pa1.Address
let secondAddress = pa2.Address
select new
{
Name = person.Name,
Street1 = firstAddress.Street,
Suburb1 = firstAddress.Suburb,
Country1 = firstAddress.Country,
Street2 = secondAddress.Street,
Suburb2 = secondAddress.Suburb,
Country2 = secondAddress.Country,
}
This causes LINQ to SQL (and Entity Framework) to generate exactly the SQL we were originally aiming for! Notice the use of DefaultIfEmpty to turn the joins into left outer joins (remember that joins in LINQ are inner joins).
At this point you may be thinking “I’ll just use Entity Framework because it seems like I can trust it to write good SQL for me”. Hold your horses my friend; let’s modify the above query just slightly and get rid of those let statements, inlining the navigation through PeopleAddress’s Address property. That’s just navigating through a many to one relation, that shouldn’t cause any problems, right?
from person in context.Persons
join pa in context.PersonAddresses on new { person.ID, Index = 1 } equals new { ID = pa.PersonID, pa.Index } into pa1s
join pa in context.PersonAddresses on new { person.ID, Index = 2 } equals new { ID = pa.PersonID, pa.Index } into pa2s
from pa1 in pa1s.DefaultIfEmpty()
from pa2 in pa2s.DefaultIfEmpty()
select new
{
Name = person.Name,
Street1 = pa1.Address.Street,
Suburb1 = pa1.Address.Suburb,
Country1 = pa1.Address.Country,
Street2 = pa2.Address.Street,
Suburb2 = pa2.Address.Suburb,
Country2 = pa2.Address.Country,
}
Wrong! Now Entity Framework is doing that retarded table join-per-column thing (the query cost is 0.0312):
SELECT [Extent1].[ID] AS [ID], [Extent1].[Name] AS [Name], [Extent4].[Street] AS [Street],
[Extent5].[Suburb] AS [Suburb], [Extent6].[Country] AS [Country], [Extent7].[Street] AS [Street1],
[Extent8].[Suburb] AS [Suburb1], [Extent9].[Country] AS [Country1]
FROM [dbo].[Person] AS [Extent1]
LEFT OUTER JOIN [dbo].[PersonAddress] AS [Extent2] ON ([Extent1].[ID] = [Extent2].[PersonID]) AND (1 = [Extent2].[Index])
LEFT OUTER JOIN [dbo].[PersonAddress] AS [Extent3] ON ([Extent1].[ID] = [Extent3].[PersonID]) AND (2 = [Extent3].[Index])
LEFT OUTER JOIN [dbo].[Address] AS [Extent4] ON [Extent2].[AddressID] = [Extent4].[ID]
LEFT OUTER JOIN [dbo].[Address] AS [Extent5] ON [Extent2].[AddressID] = [Extent5].[ID]
LEFT OUTER JOIN [dbo].[Address] AS [Extent6] ON [Extent2].[AddressID] = [Extent6].[ID]
LEFT OUTER JOIN [dbo].[Address] AS [Extent7] ON [Extent3].[AddressID] = [Extent7].[ID]
LEFT OUTER JOIN [dbo].[Address] AS [Extent8] ON [Extent3].[AddressID] = [Extent8].[ID]
LEFT OUTER JOIN [dbo].[Address] AS [Extent9] ON [Extent3].[AddressID] = [Extent9].[ID]
Incidentally, if you put that query through LINQ to SQL, you’ll find it can deal with the inlined navigation properties and it still generates the correct query (sigh!).
So what’s the lesson here? The lesson is that you must always keep a very close eye on what SQL your LINQ providers are writing for you. A tool like LINQPad may be of some use, as you can write your queries in it and it’ll show you the generated SQL. Although Entity Framework does a better job with SQL generation than LINQ to SQL, as evidenced by it being able to handle our first, more intuitive, LINQ query, it’s still fairly easy to trip it up and get it to write badly performing SQL, so you still must keep your eye on it.
Incremental Builds in MSBuild and How to Avoid Breaking Them
June 26, 2011 2:50 PM by Daniel Chambers
One of my recent tasks at a client has been to help improve the speed of their build process. They have around 140 projects in their main Visual Studio solution, and one of the problems they had was that if they changed some code in a unit\integration test project at the bottom of the compile chain, Visual Studio would rebuild most of the projects that the test project depended upon either directly or indirectly, wasting developer time as she or he is forced to wait a minute or two while everything compiles. This is obviously unnecessary, as changing code in only the test project should only require a rebuild of the test project and not its unchanged dependencies. Visual Studio is capable of avoiding unnecessary rebuilds, as its build system is powered by MSBuild, but unless you understand how this system works it is possible to accidentally break it.
MSBuild supports the idea of “incremental builds”. Essentially, each MSBuild target (such as Build, Clean, etc) can be told what its input and output files are. If you think about a target that takes source code and produces an assembly, the inputs are the source code files and the outputs are the compiled assembly. MSBuild checks the timestamps of the input files and if they are newer than the timestamps of the output files, it assumes the outputs are out of date and need to be regenerated by whatever process is contained within the target. If the output files are the same age or older than the input files, MSBuild will skip the target.
Here’s a practical example. Create a folder on your computer somewhere and create a Project.proj file in it which can contain this:
<?xml version="1.0" encoding="utf-8"?>
<Project ToolsVersion="4.0" DefaultTargets="CopyFiles" xmlns="http://schemas.microsoft.com/developer/msbuild/2003">
<PropertyGroup>
<DestinationFolder>Destination</DestinationFolder>
</PropertyGroup>
<ItemGroup>
<File Include="Source.txt"/>
</ItemGroup>
<Target Name="CopyFiles"
Inputs="@(File)"
Outputs="@(File -> '$(DestinationFolder)\%(RelativeDir)%(Filename)%(Extension)')">
<Copy SourceFiles="@(File)" DestinationFolder="$(DestinationFolder)" />
</Target>
</Project>
This is a very simple MSBuild script that copies the files specified by the File items into the DestinationFolder. Note how the CopyFiles target has its input set to the File items and the outputs set to the copied files (that “–>” syntax is an MSBuild transform that transforms the paths specified by the File items into their matching copy destination paths).
If you create that Source.txt file next to the .proj file and run MSBuild in that folder, you will see it create the Destination folder and copy Source.txt in there. It didn’t skip the CopyFiles target because it looked for the output (Destination\Source.txt) and couldn’t find it.

MSBuild copies the file as the output file does not exist
However, If you run MSBuild again you will notice that it skips the CopyFiles target as it has figured out that the timestamp on Source.txt is the same as the timestamp on Destination\Source.txt and therefore it doesn’t need to run the CopyFiles target again.

MSBuild skips the copy as the output is the same age as the input
Now if you go change the contents of Source.txt and run MSBuild again, you’ll notice that it will copy the file over again, as it notes the input file is now newer than the output file.
As Visual Studio uses MSBuild to power the build process, it supports incremental builds too. Files in your project (such as source files) as used as input files within Microsoft’s build pipeline and the generated outputs are things like assembly files, XMLDoc files, etc. So if your source files are newer than your assembly, Visual Studio will rebuild the assembly.
However, some parts of the build pipeline are not intelligent about input and output files and as such, when you use them, you can accidentally break incremental builds. In particular, it’s quite easy to break incremental builds by using pre-build events in Visual Studio. For example, imagine you were using the pre-build event to run a custom executable that generates some C# code from an XML file, where this C# code is included in your project and will be compiled into your assembly:

Some custom code generation being performed in a pre-build event in Visual Studio
Unfortunately, since you can put whatever you like in the pre-build event box, MSBuild has no way of determining what are the input files and what are the output files involved when running the stuff you enter in there, so it just runs it every time. This has the nasty effect, in this case, of regenerating Code.cs upon every build (assuming MyCodeGenerator.exe isn’t smart enough to detect that it doesn’t need to do a regeneration), which will break incremental builds as now one of the inputs for your assembly (Code.cs) is newer than the last built assembly!
Thankfully this is easy to fix by moving your call to MyCodeGenerator.exe out of the pre-build event and into a custom MSBuild target like so:
<ItemGroup>
<CodeGenInput Include="Input.xml">
<Visible>false</Visible>
</CodeGenInput>
<CodeGenOutput Include="Code.cs">
<Visible>false</Visible>
</CodeGenOutput>
</ItemGroup>
<Target Name="GenerateCode" Inputs="@(CodeGenInput)" Outputs="@(CodeGenOutput)">
<Exec Command="MyCodeGenerator.exe -In @(CodeGenInput) -Out @(CodeGenOutput)" />
</Target>
<Target Name="BeforeBuild" DependsOnTargets="GenerateCode">
</Target>
The above MSBuild snippet defines both the input file and the output file as items, with the Visible metadata set to false in order to stop the items from showing up in Visual Studio. The GenerateCode target is hooked into the Microsoft build pipeline by defining the standard BeforeBuild target and specifying that it depends upon the GenerateCode target. This will cause it to run before the build process starts. The target does what the pre-build event did before, but now the inputs and the outputs are defined, which allows MSBuild to successfully skip the code generation where necessary.
In conclusion, we’ve seen how it is well within MSBuild’s (and therefore Visual Studio’s) ability to perform incremental builds, skipping time consuming targets in order to not repeat work unnecessarily. You may not notice the saved time on small projects, but when you start having build processes that take minutes to complete builds, incremental builds can start saving you lots of time as one minute over and over again in every day adds up to a lot of time very quickly! It can be easy to break incremental builds by using the build events in Visual Studio to change input files at build time, but now that you’re armed with the knowledge of how incremental builds work, you can easily shift those tasks into proper targets in your project file and support incremental builds.
Sweeping Yucky LINQ Queries Under the Rug with Expression Tree Rewriting
May 02, 2011 2:06 PM by Daniel Chambers (last modified on May 03, 2011 6:43 AM)
In my last post, I explained some workarounds that you could hack into your LINQ queries to get them to perform well when using LINQ to SQL and SQL CE 3.5. Although those workarounds do help fix performance issues, they can make your LINQ query code very verbose and noisy. In places where you’d simply call a constructor and pass an entity object in, you now have to use an object initialiser and copy the properties manually. What if there are 10 properties (or more!) on that class? You get a lot of inline code. What if you use it across 10 queries and you later want to add a property to that class? You have to find and change it in 10 places. Did somebody mention code smell?
In order to work around this issue, I’ve whipped up a small amount of code that allows you to centralise these repeated chunks of query code, but unlike the normal (and still recommended, if you don’t have these performance issues) technique of putting the code in a method/constructor, this doesn’t trigger these performance issues. How? Instead of the query calling into an external method to execute your query snippet, my code takes your query snippet and inlines it directly into the LINQ query’s expression tree. (If you’re rusty on expression trees, try reading this post, which deals with some basic expression trees stuff.) I’ve called this code the ExpressionTreeRewriter.
The Rewriter in Action
Let’s set up a little (and very contrived) scenario and then clean up the mess using the rewriter. Imagine we had this entity and this DTO:
public class PersonEntity
{
public int ID { get; set; }
public string FirstName { get; set; }
public string LastName { get; set; }
}
public class PersonDto
{
public int EntityID { get; set; }
public string GivenName { get; set; }
public string Surname { get; set; }
}
Then imagine this nasty query (if it’s not nasty enough for you, add 10 more properties to PersonEntity and PersonDto in your head):
IQueryable<PersonDto> people = from person in context.People
select new PersonDto
{
EntityID = person.ID,
GivenName = person.FirstName,
Surname = person.LastName,
};
Normally, you’d just put those property assignments in a PersonDto constructor that takes a PersonEntity and then call that constructor in the query. Unfortunately, we can’t do that for performance reasons. So how can we centralise those property assignments, but keep our object initialiser? I’m glad you asked!
First, let’s add some stuff to PersonDto:
public class PersonDto
{
...
public static Expression<Func<PersonEntity,PersonDto>> ToPersonDtoExpression
{
get
{
return person => new PersonDto
{
EntityID = person.ID,
GivenName = person.FirstName,
Surname = person.LastName,
};
}
}
[RewriteUsingLambdaProperty(typeof(PersonDto), "ToPersonDtoExpression")]
public static PersonDto ToPersonDto(PersonEntity person)
{
throw new InvalidOperationException("This method is a marker method and must be rewritten out.");
}
}
Now let’s rewrite the query:
IQueryable<PersonDto> people = (from person in context.People
select PersonDto.ToPersonDto(person)).Rewrite();
Okay, admittedly it’s still not as nice as just calling a constructor, but unfortunately our hands are tied in that respect. However, you’ll notice that we’ve centralised that object initialiser snippet into the ToPersonDtoExpression property and somehow we’re using that by calling ToPersonDto in our query.
So how does this all work? The PersonDto.ToPersonDto static method is what I’ve dubbed a “marker method”. As you can see, it does nothing at all, simply throwing an exception to help with debugging. The call to this method is incorporated into the expression tree constructed for the query (stored in IQueryable<T>.Expression). This is what that expression tree looks like:

The expression tree before being rewritten
When you call the Rewrite extension method on your IQueryable, it recurs through this expression tree looking for MethodCallExpressions that represent calls to marker methods that it can rewrite. Notice that the ToPersonDto method has the RewriteUsingLambdaPropertyAttribute applied to it? This tells the rewriter that it should replace that method call with an inlined copy of the LambdaExpression returned by the specified static property. Once this is done, the expression tree looks like this:
")
The expression tree after being rewritten (click to enlarge)
Notice that the LambdaExpression’s Body (which used to be the MethodCallExpression of the marker method) has been replaced with the expression tree for the object initialiser.
Something to note: the method signature of marker method and that of the delegate type passed to Expression<T> on your static property must be identical. So if your marker method takes two ClassAs and returns a ClassB, your static property must be of type Expression<Func<ClassA,ClassA,ClassB>> (or some delegate equivalent to the Func<T1,T2,TResult> delegate). If they don’t match, you will get an exception at runtime.
Rewriter Design

Expression Tree Rewriter Design Diagram
The ExpressionTreeRewriter is the class that implements the .Rewrite() extension method. It searches through the expression tree for called methods that have a RewriterMarkerMethodAttribute on them. RewriterMarkerMethodAttribute is an abstract class, one implementation of which you have already seen. The ExpressionTreeRewriter uses the attribute to create an object implementing IExpressionRewriter which it uses to rewrite the MethodCallExpression it found.
The RewriteUsingLambdaPropertyAttribute creates a LambdaInlinerRewriter properly configured to inline the LambdaExpression returned from your static property. The LambdaInlinerRewriter is called by the ExpressionTreeRewriter to rewrite the marker MethodCallExpression and replace it with the body of the LambdaExpression returned by your static property.
The other marker attribute, RewriteUsingRewriterClassAttribute, allows you to specify a class that implements IExpressionRewriter which will be returned to the rewriter when it wants to rewrite that marker method. Using this attribute gives you low level control over the rewriting as you can create classes that write expression trees by hand.
The EntityNullTestRewriter is one such class. It takes a query with the nasty nullable int performance hack:
IQueryable<IntEntity> queryable = entities.AsQueryable()
.Where(e => (int?)e.ID != null)
.Rewrite();
and allows you to sweep that hacky code under the rug, so to speak:
IQueryable<IntEntity> queryable = entities.AsQueryable()
.Where(e => RewriterMarkers.EntityNullTest(e.ID))
.Rewrite();
RewriterMarkers.EntityNullTest looks like this:
[RewriteUsingRewriterClass(typeof(EntityNullTestRewriter))]
public static bool EntityNullTest<T>(T entityPrimaryKey)
{
throw new InvalidOperationException("Should not be executed. Should be rewritten out of the expression tree.");
}
The advantage of EntityNullTest is that people can look at its documentation to see why it’s being used. A person new to the project, or who doesn’t know about the performance hacks, may refactor the int? cast away as it looks like pointless bad code. Using something like EntityNullTest prevents this from happening and also raises awareness of the performance issues.
Give Me The Code!
Enough chatter, you want the code don’t you? The ExpressionTreeRewriter is a part of the DigitallyCreated Utilities BCL library. However, at the time of writing (changeset 4d1274462543), the current release of DigitallyCreated Utilities doesn’t include it, so you’ll need to check out the code from the repository and compile it yourself (easy). The ExpressionTreeRewriter only supports .NET 4, as it uses the ExpressionVisitor class only available in .NET 4; so don’t accidentally use a revision from the .NET 3.5 branch and wonder why the rewriter is not there.
I will get around to making a proper official release of DigitallyCreated Utilities at some point; I’m slowly but surely writing the doco for all the new stuff that I’ve added, and also writing a proper build script that will automate the releases for me and hopefully create NuGet packages too.
Conclusion
The ExpressionTreeRewriter is not something you should just use willy-nilly. If you can get by without it by using constructors and method calls in your LINQ, please do so; your code will be much neater and more understandable. However, if you find yourself in a place like those of us fighting with LINQ to SQL and SQL CE 3.5 performance, a place where you really need to inline lambdas and rewrite your expression trees, please be my guest, download the code, and enjoy.